Thank you Amelia and Noah for trying Leo out and sharing your feedback! I appreciate you both taking the time to test things and let us know about your experience. Hopefully despite a few bumps along the way, you still got some useful results.
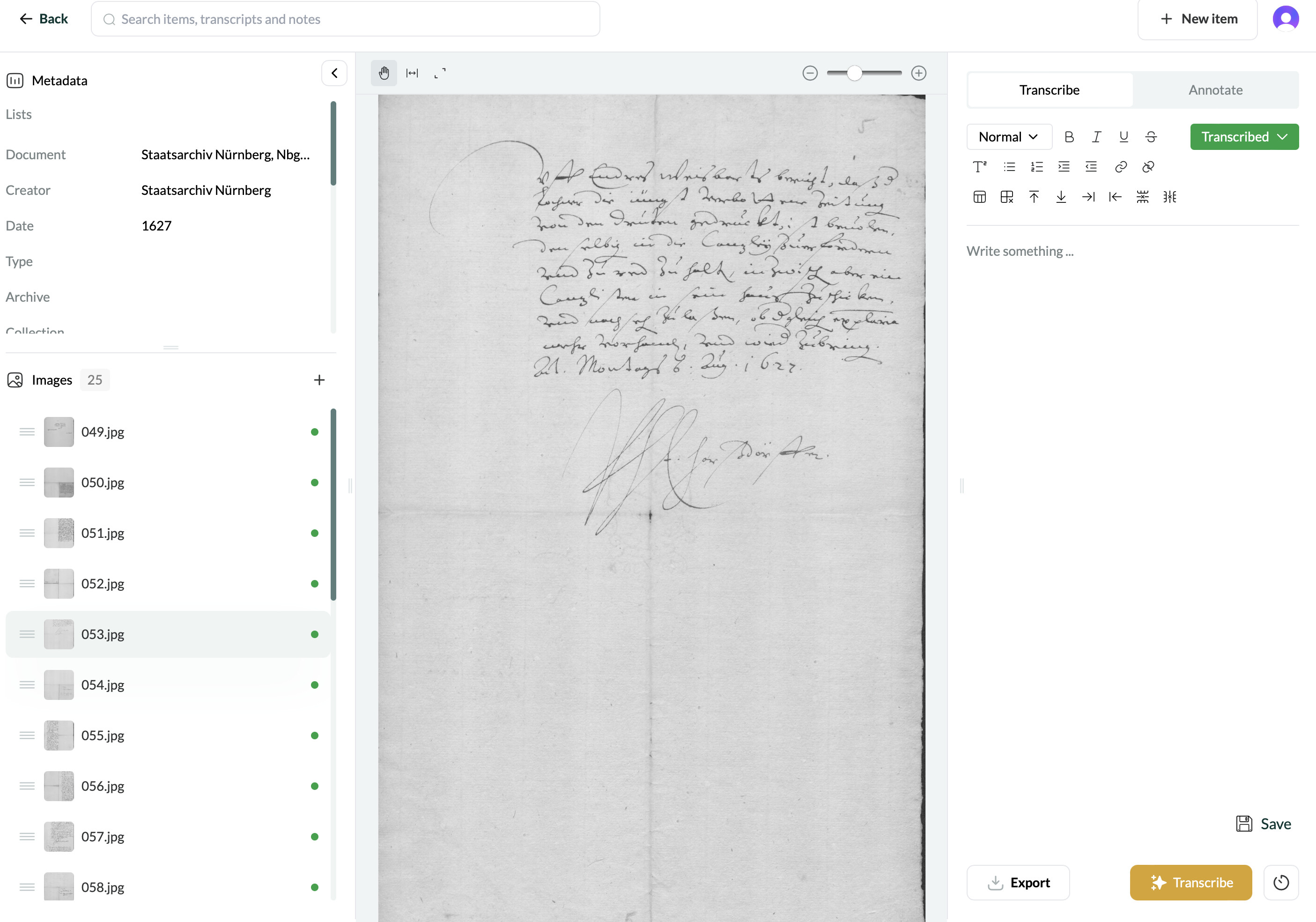
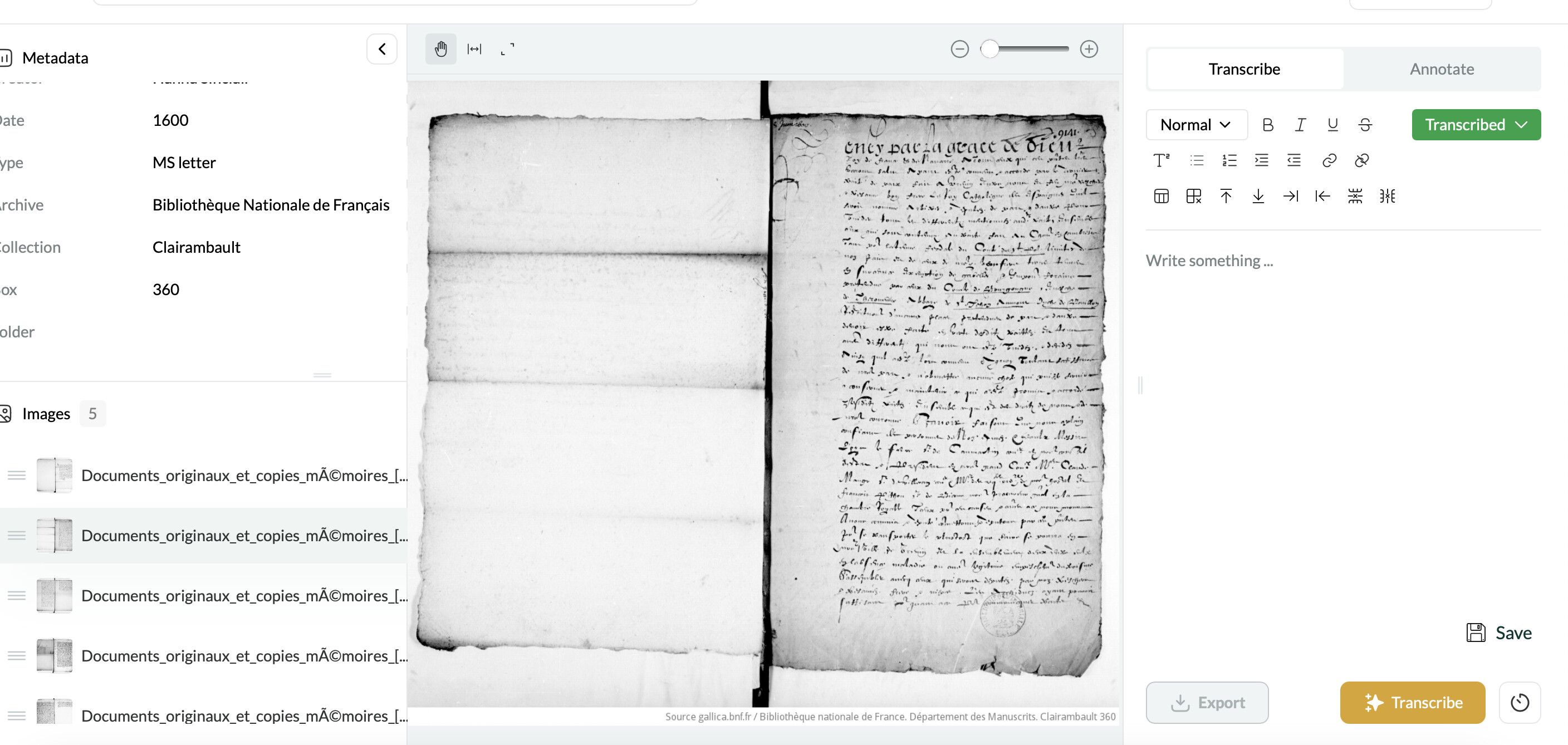
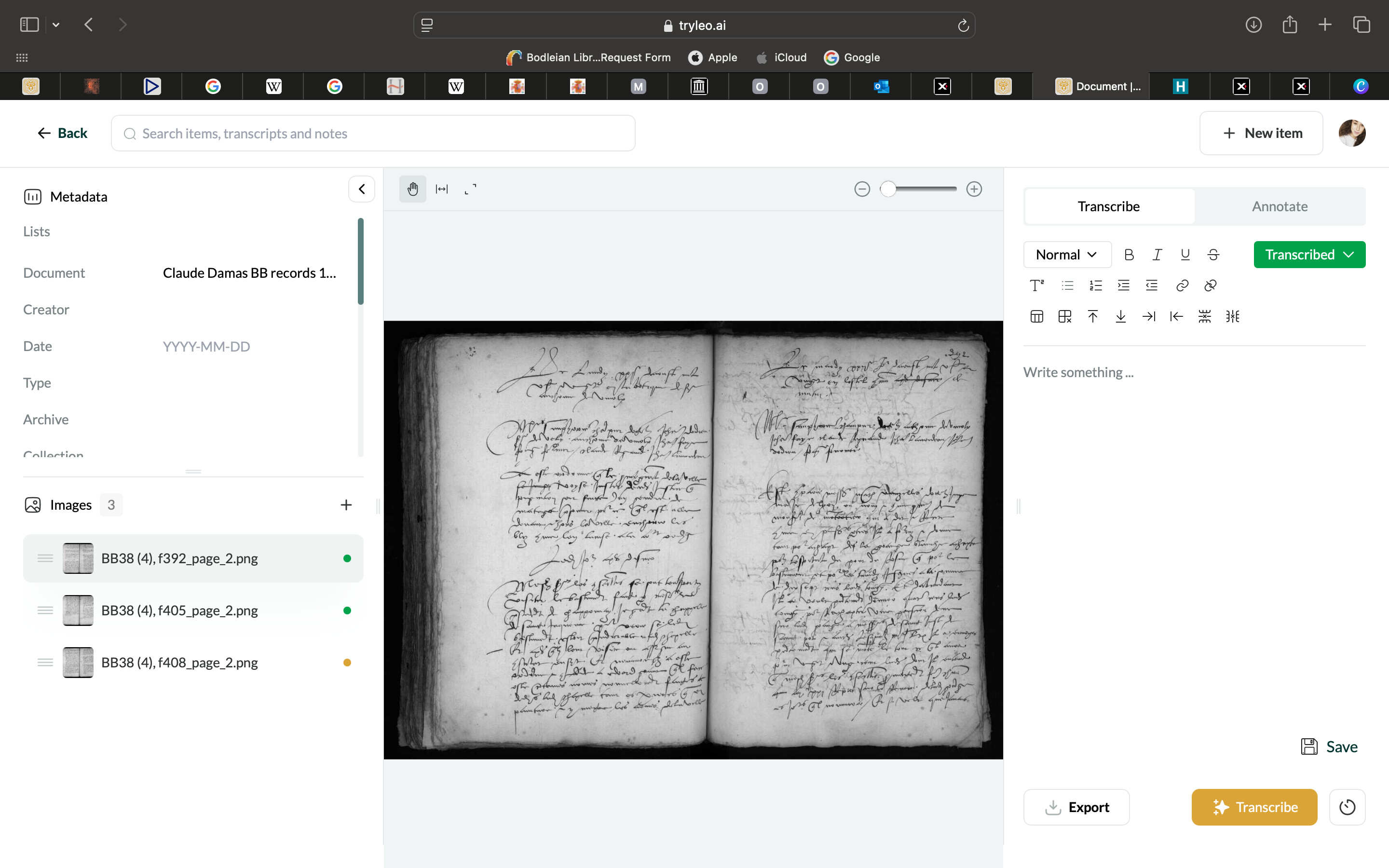
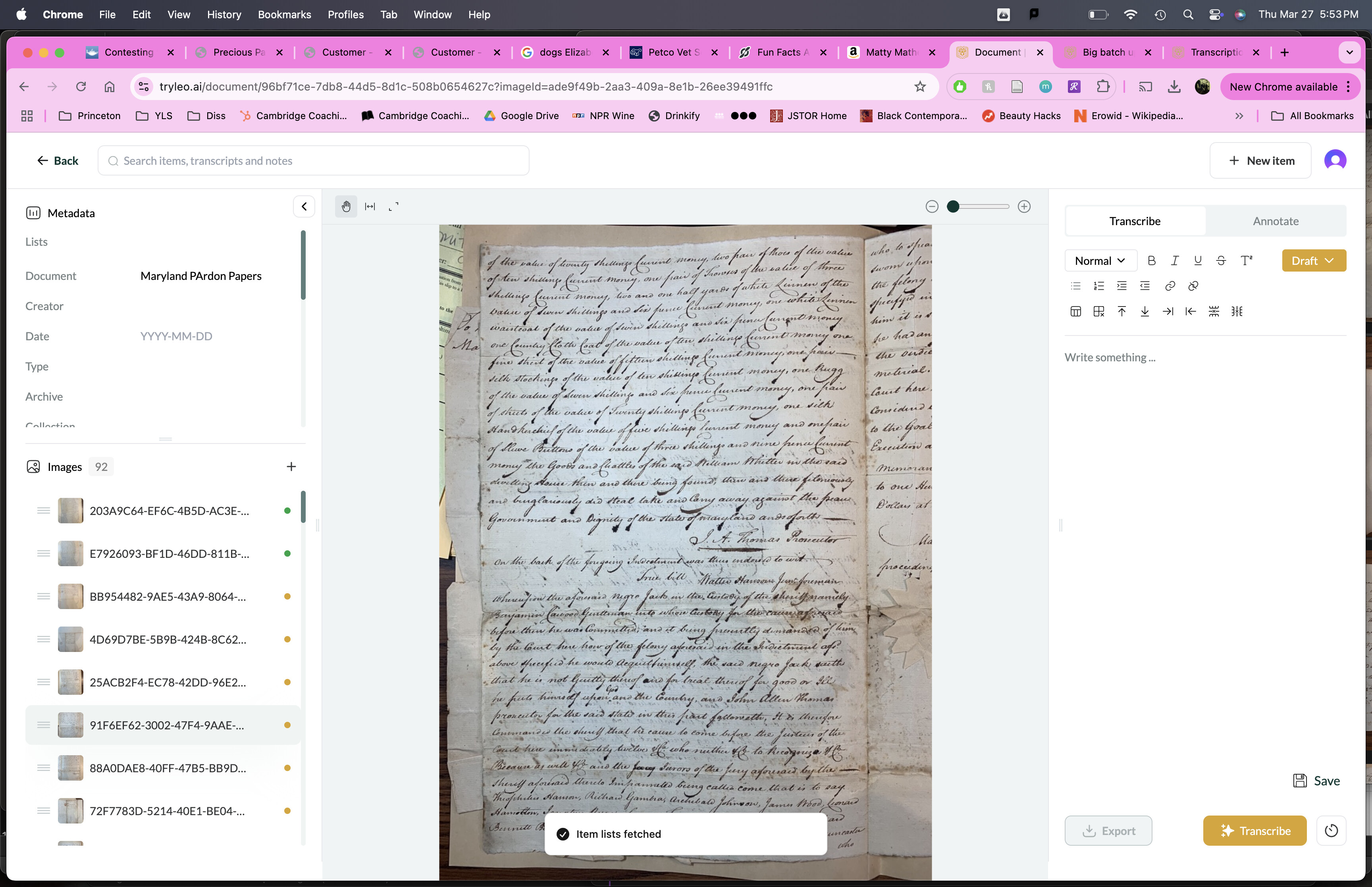
It’d be really helpful if you could keep an eye on the types of images that Leo struggles to produce transcripts for. If you notice any consistent patterns in the nature of the manuscripts, image formats, or other factors, please do share. Amelia’s 32% failure rate is very high for images within our model’s training distribution, so having a more granular understanding of what’s happening here would help us a lot.
When a transcription fails, an error message should appear, and you shouldn’t be charged a credit. But note there are two possible senses in which a transcription can be said to fail:
- The model knows that it has failed and sends a failed error response
- The model delivers a response that it thinks was successful but the transcript is blank
It seems like the issue here relates to the second, more challenging case. While we’re looking into this and working on a fix, we’d be happy to top up your account to compensate for any lost credits. Just let us know roughly how many credits were affected, and we’ll sort that out on our end.
Dealing with and detecting transcription failures is a greater technical challenge than it might seem on first glance. From our perspective there are some significant issues to work through:
- If no credit is charged for transcription failures, then we need a safety mechanism to prevent users overwhelming our system by requesting potentially infinite numbers of transcriptions that are bound to fail. This is because knowing whether a transcription fails actually costs us the same amount in computing power as if a transcription is successful. So we need some way for the system to time out but we wouldn’t want this to affect users who are using the service legitimately.
- Additionally, and relatedly, it is very difficult for us to get the model to detect whether a transcription has failed. For instance, is the result empty because the uploaded image did not contain any text? In that case, the transcription should be deemed successful. Also, at what point do we define when a transcription is wrong and how can we detect this without developing a model with a superior capability than the one we already have?
Leo ideally would work with two-page spreads, but success can depend on factors like page size and text density. Unfortunately, due to the present constraints of the technology, we can’t make promises about exactly what content would be within the defined scope of a single image.
In preparation for the beta release, our focus has been on ensuring core functionality like this works smoothly before adding extra features. If image editing tools like rotating, cropping, or inverting are things you’d like to see in the future, please post about that here: Feature Suggestions - Leo.
Thanks again for your thoughts—these are exactly the kinds of issues we’re hoping to refine through beta testing. So please continue to provide any further details about when transcription failures occur and whether you’re getting an error message or not. We really appreciate it.