I’m a bit late to getting started here, but have now begun experimenting with Leo after returning from a few weeks in the archives. Obviously, it’s extraordinarily helpful in many ways, so my sincere thanks for all the work in creating it and getting it running. Its knowledge of secretary hand is really impressive.
But my main question (for anyone) is this: Who are the intended users of AI transcription software? Insofar as it’s people with training in paleography (or the relevant skillset) who are simply using it to get a baseline transcription and then go back and manually check for errors, it’s clearly great and can save a TON of time. But my worry is about people (whether inside or outside the academy) using it without the training/knowledge to check for accuracy, etc. Are undergraduates going to try to start incorporating (likely digitized) manuscripts into term papers/senior theses? Is the College Board going to start including digitized manuscripts in DBQs for AP courses (in the U.S.)? Are incoming graduate students simply going to decide they don’t need to learn paleography and try to write a manuscript-based dissertation? A few years ago, I did a summer intensive course in paleography (mainly secretary hand), which proved to be one of the most helpful things I’ve ever done. But I worry about the perceived need for courses like that and the fate of paleography training at large in an AI world. So, I don’t mean to sound like I’m scaremongering or a complete Luddite here, but I also have a lot of questions about how these platforms will be used in the broader society. (With the knowledge that Leo isn’t the first and these already exist in various forms). But once they’re out there, can anyone really control how they’re used? And who they’re used by?
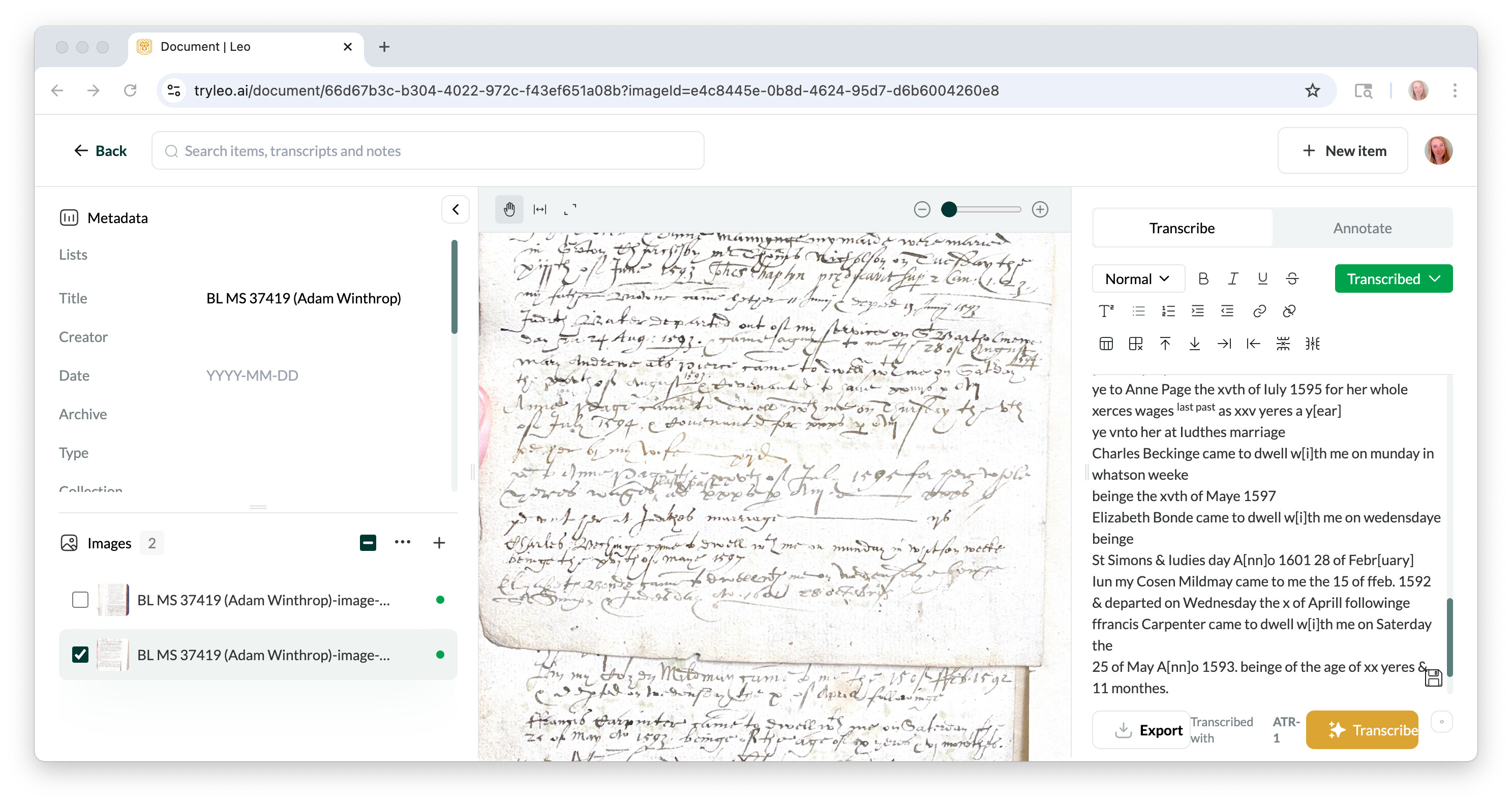
Obviously, I know that the point of software like this is to get a basic transcription - rather than a flawless one - and minor errors are to be expected. But to take one example in the attached screenshot, Leo read the word “yeres” as “xerces,” the Roman numerals “xxx” as “xxv” and the word “whitsun” as “whatson.” I’m not bothered by small errors like these for my own purposes. But I do wonder how they make us think about putting a tool like this into the hands of the broader public? But again, that goes back to the “Who are these tools for?” question. And if it’s just trained paleographers trying to save some time and energy, then all is fine.