I think it would be helpful if there were something that helped flag Leo’s confidence in its transcriptions/predictions. Maybe if someone hovered over a word in the transcription, it would give a metric of the program’s confidence that the transcribed word is correct, for example. Or maybe some system like color coding in which a user gets some sort of visual warning when Leo is less confident in specific words it transcribed [e.g. orange text when the program is somewhat confident that the word is correct or red text when the program is not at all confident in its best guess].
I don’t even know if “confidence” metrics are something that are part of Leo’s transcription process and could be made to users, but I bring this up because I’ve noticed in some transcriptions that Leo will produce transcriptions with words that sort of make contextual sense (based on a prediction from a language model?), but the “guessed” words are not actually correct.
I’ve included a screenshot to show what I mean:
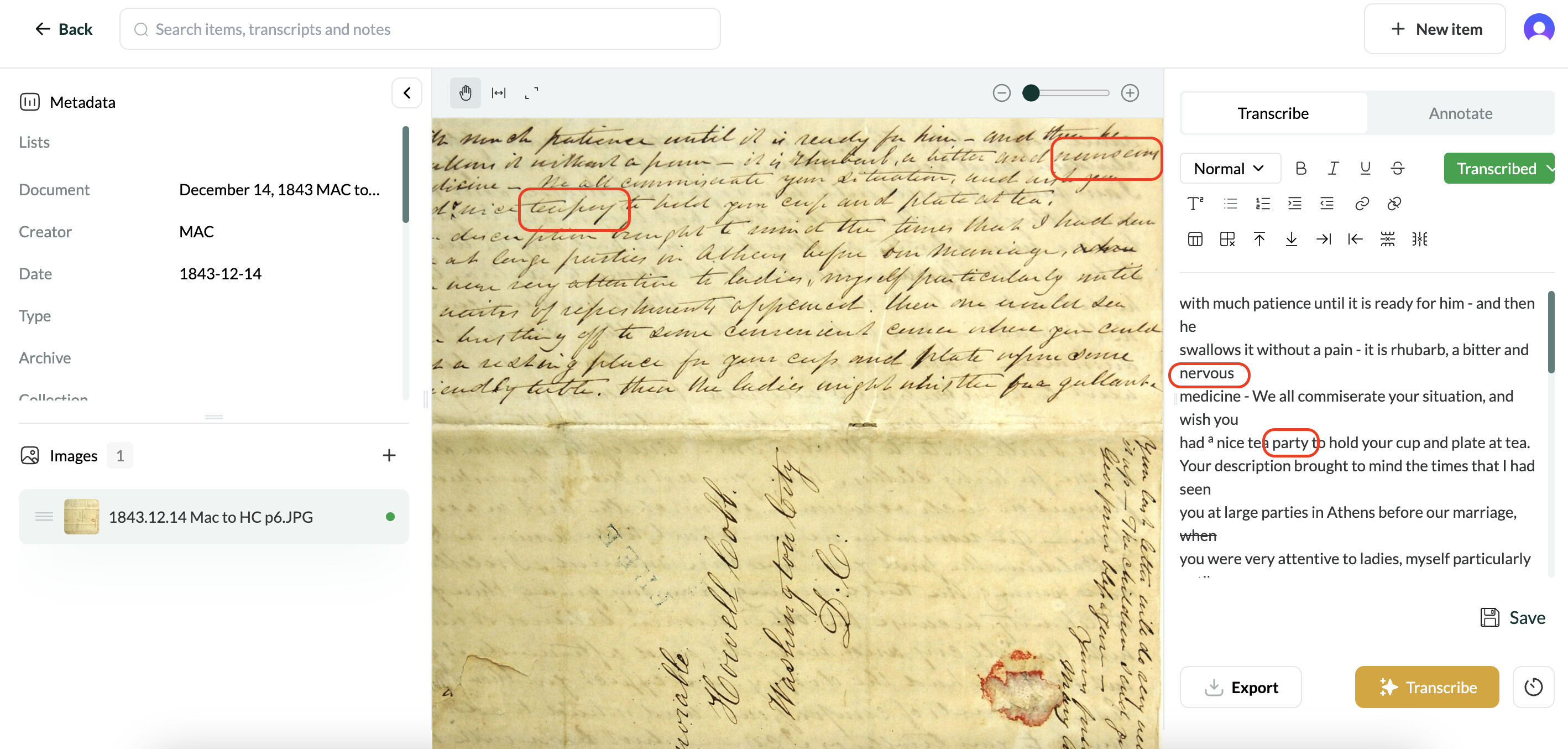
I’ve marked two instances where Leo predicted the wrong words, even though the words Leo produced somewhat make sense based on the context. I know that the first word is “nauseous,” but I’m not 100% sure of the second word (maybe “tea press”?). In the case of the latter, I would rather use brackets or some sort of editorial indication of uncertainty rather than use an incorrect word.
Some of these are easy enough to catch if a user reads the actual document very carefully side by side with the transcription (as they should), but I think having some sort of visual cue regarding which transcribed words should receive particular evaluation would make this process easier. My eyes can glaze over with transcription work, and for anyone else like me, it’s easy to get make mistakes while trying to move through documents quickly. Something incorporated into Leo’s transcription output that stops a user in their tracks and suggests that they pay extra attention to evaluating specific elements of the document could help prevent erroneous transcriptions.