This is somewhat similar to some suggestions that have been made before, but a different approach I think to solving it. I think it would be useful if we could manually tell the programme what a discrete ‘box’ of text is as well as its orientation. So if you have a page with a ‘main text’ and two bits of marginalia, both oriented sideways, you could indicate to the programme that there are 3 discrete text boxes.
This might also have the benefit of forcing the AI to transcribe marginalia whereas now it sometimes ignores it, as in this screenshot.
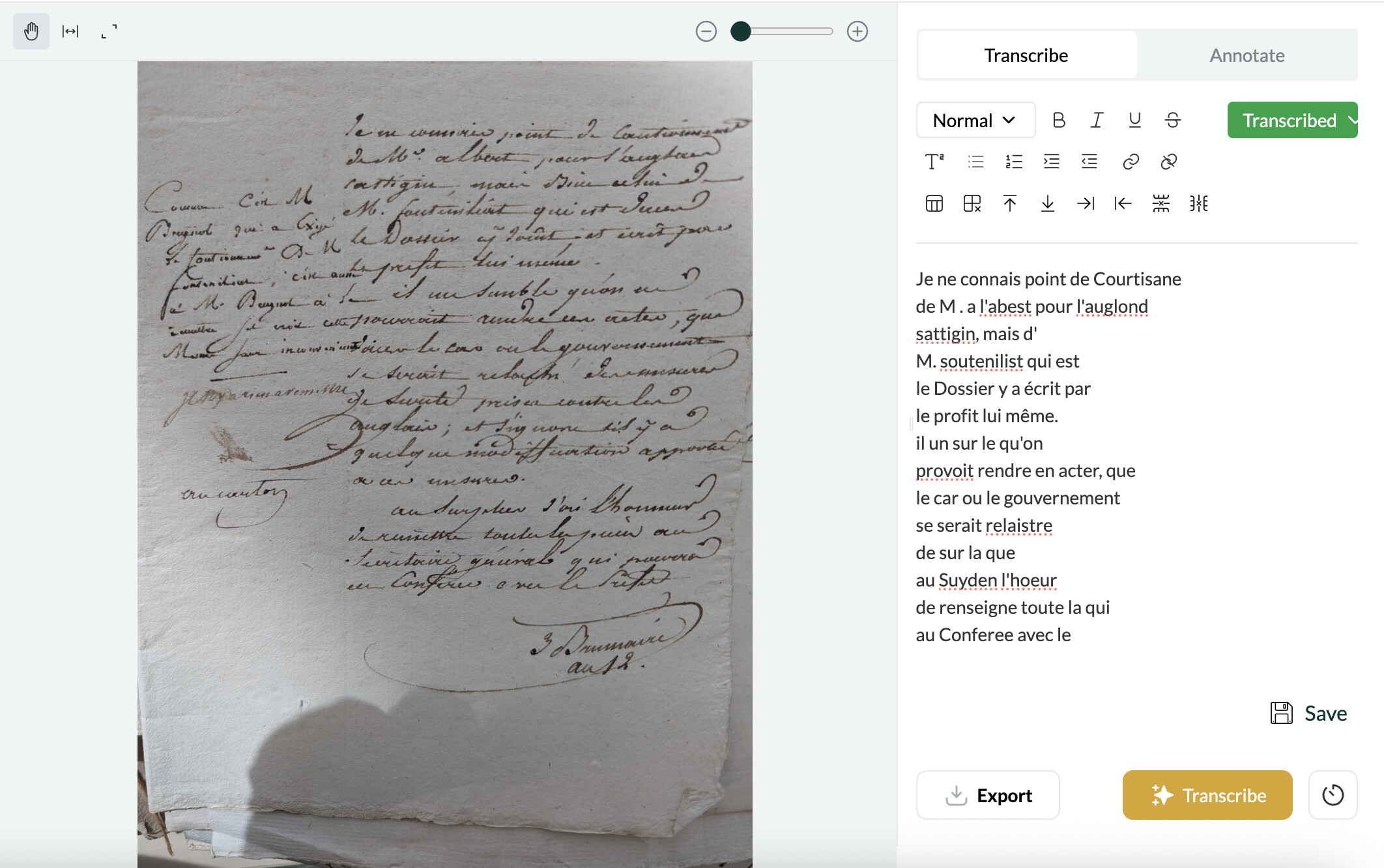
Hey both! Segmentation (dividing the input image into meaningful units like columns, tables, lines, words, and characters) is one of the most challenging problems in HTR (handwritten text recognition) technology. Some HTR services use a first-step computer vision process to create bounding boxes in the way that you describe, before then “reading” the content, for instance line by line or even character by character. Leo’s model architecture delivers more accurate transcriptions by interpreting the image holistically, but one downside is that it doesn’t currently preserve location information (i.e., coordinates for text).
Our first aim is to ensure that the model always transcribes all text on the page, so that no text in complex layout structures is ignored. We’re making speedy progress with this and an updated version of the model that better preserves all text should be out in the next week or two. Then, we want to find some way to match parts of the image with the transcript, so that the user can hover over transcription text and it will highlight the relevant part of the image. This is a much more complex task but it is a priority for development in the intermediate term.
As a shorter term solution we are currently working on developing image manipulation tools (including cropping) so that if the model does miss out some text, you’ll easy be able to select that portion and transcribe it in the web app.
2 Likes
Thanks for the explanation and great that you’re working on something to that end!
After the beta, if the model doesn’t catch a bit of a text and a user crops the image to focus on the bit it missed, would that count as a new transcription request and take a credit, or are you thinking of having some sort of ‘free retry’, a sort of mea culpa of the algorithm if that makes sense?
At the moment the plan is to offer these features separately. Soon, there’ll be a free option to retry a transcription. And we’ve introduced image manipulation tools including cropping in the latest version of Leo. See here: Version 0.1.9 released