Homoeopathy is the subject of two letters that Leo transcribed for me. In the first letter, homoeopathy and related words are all spelled correctly, but Hahnemann, who even Google’s often-clueless AI bot recognizes as the founder of homoeopathy, shows up as Kuhnemann and Nahmemann. In the next letter it’s Nahnemann, while homoeopathy is again usually spelled correctly (although in one case someone is identified as a “hauncopathist”). Perhaps Leo could be taught to figure out that a name ending “ahnemann” in a letter filled with homoeopathy references starts with H? (I assume this is generalizable to other relauively famous people). A realted question, regarding “hauncopathist”: can you help Leo get better at scanning other words in a document to find a match, when the word it came up with isn’t a word? This happened in a different letter where “sensuous” was transcribed correctly at the top of the page but came out as “ruminous” later in the document.
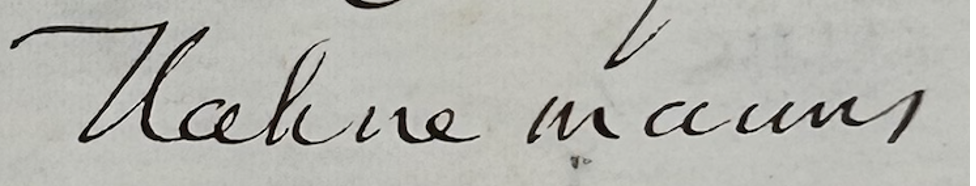
I see what you mean about Hahnemann/ Kuhnemann/ Nahmemann. I think the fundamental problem here is that Leo isn’t familiar with the way that e.g. H (in Hahnemann) and s/e (in sensuous) are written in this handwriting style. Our aim is to teach the model by showing it more examples of correct transcripts.
An alternative approach would be to “clean” the transcript afterwards, e.g. by plugging the raw transcript into an LLM and asking it to make conjectural corrections, based on its knowledge about the world, of homeopathy and everything else. The issue with this approach is that it is liable to overcorrection. If a letter writer makes a mistake or even uses a non-standard word, we want to provide the user with an accurate transcription that preserves that mistake rather than removing it, if you see what I mean.
Yes, I absolutely see that – my letter-writer is also not a perfect speller, and I find myself wondering if Leo is making “silent edits” without my being aware of it (since I typically only catch Leo’s mistakes via spell-checking or just eye-balling the transcript). For instance: my guy spelled “Brobdingnagian” Brobdignaggian, and Leo’s version was “Probbdignaggian.” There’s probably no perfect solution here.
I guess what I was getting at, though, is that you might be able to train Leo to search within a document for contextual clues when he runs into a word where the transcription is not a word (e.g. ruminous), since words tend to reappear in the same document; or, assuming he got Hahnemann right once, he might be able to make the homoeopathy connection and correct the ones he got wrong…
I definitely think using more context clues, both from other images in the same document and from item-level metadata as you suggested elsewhere, is very smart and I’ll talk to Jack about how we can do it. One challenge is that it’d be more expensive due to extra GPU time, so maybe we’d need to introduce some kind of supercharged transcription setting (like ChatGPT’s “Deep Research”) that costs a little extra.
A couple of other points:
- We plan to highlight token-level confidence scores to assist users in reviewing transcripts. So if Leo isn’t sure about “Probbdignaggian”, that’ll be highlighted for review. @Laura_Nelson helpfully suggested this a while ago here.
- Something else that we’re currently working on, which would address this issue for larger datasets, is the ability for users to fine-tune Leo by correcting transcriptions. The current plan depends on users correcting whole transcripts, as explained below. But ideally in the future Leo would also learn from single-word/ smaller corrections too.
This feedback is really helpful for us to think through these problems so thank you!