I have been running transcriptions on 17th century English quarter sessions examinations, and generally the results are excellent. The spellings in the transcriptions often need correcting, but it is rare for whole words to be wrong. As expected, it struggles more with names and places (though less so with the latter in fact). But one thing it routinely gets wrong is Roman numerals: prices are often listed in the format ‘xviij’ or ‘xij’ etc, and Leo rarely gets the number right, often miscounting the number of 'i’s or confusing x and v. I guess this is to do with how it works, right? It isn’t reading the specific characters, but is using context, so it is effectively guessing at the exact number. I’m not sure if this is something it will improve at, or something that will need a lot of correcting.
2 Likes
I’ve noticed something similar with Roman numerals. We’ll look into it. Thank you, Mark!
Boosting this and providing a screenshot of a particularly challenging example. This format for rendering M and D is not standard Roman numerals, but is common when writing the year in 17th century letters. (The year here is 1643.)
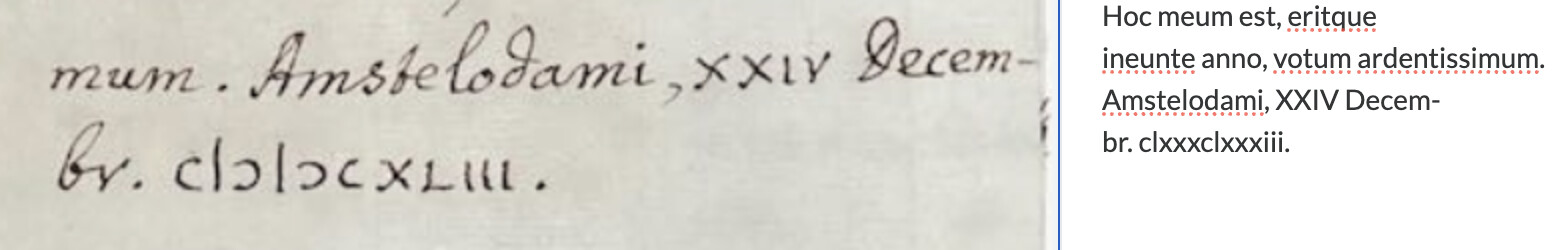
(FWIW, ChatGPT has no problem translating CIƆIƆCXLIII as 1643.)
1 Like
On another document I got this peculiar result. Leo correctly deciphered the year and translated it into Arabic numerals, but tacked on part of the original Roman numerals.
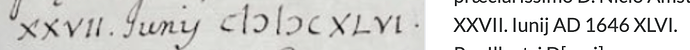
Also inserting AD is not good!
1 Like