While testing, I used different types of documents: archival files with typewritten text; handwritten archival files; newspapers (clippings and whole pages); and a printed fragment in pre-revolutionary Russian alphabet. Among them were clean documents without damage and documents with scuffs or inscriptions over the printed text. In sum, I have several observations in several types of documents:
-
Visual items.
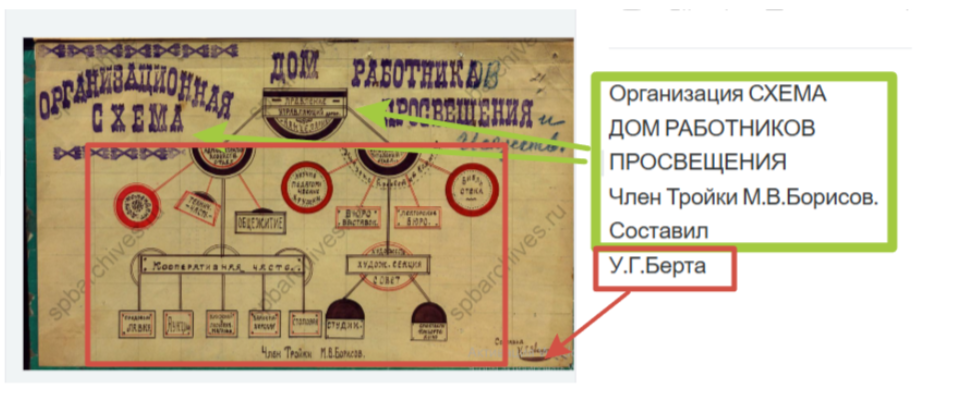
In a graph, Leo transcribed very good one part but totally skipped the others which are not less visible. Leo does well with handwritten letters (I’ll describe this below), but here it refused to recognize them. Could this be due to the fact that the graph contains words written in different formats (compare title and schema)? I highlighted here in green what Leo transcribed correctly and in red what he didn’t recognize correctly or at all.
-
Screenshots.
Leo is generally correct in transcribing screenshots of typewritten texts from digital copies on archive websites. In my case, such documents are typewritten in blue font on yellow paper, and the digital copy contains the archives’ copyright watermark across the page (see a fragment below). Leo substitutes or transcribes incorrectly about 30 percent of the words on a page, for example:
- вдимить (vdimit
) instead of *выдвинуть* (vydvinut`) - обедетненного (obedetnennogo) instead of объединенного (ob`edinennogo)
- бюллетеки (byulleteki) instead of бюллетени (byulleteni).
I can provide more examples of such errors if needed for further development to find out which letters are mixed.

-
My photos of the pages.
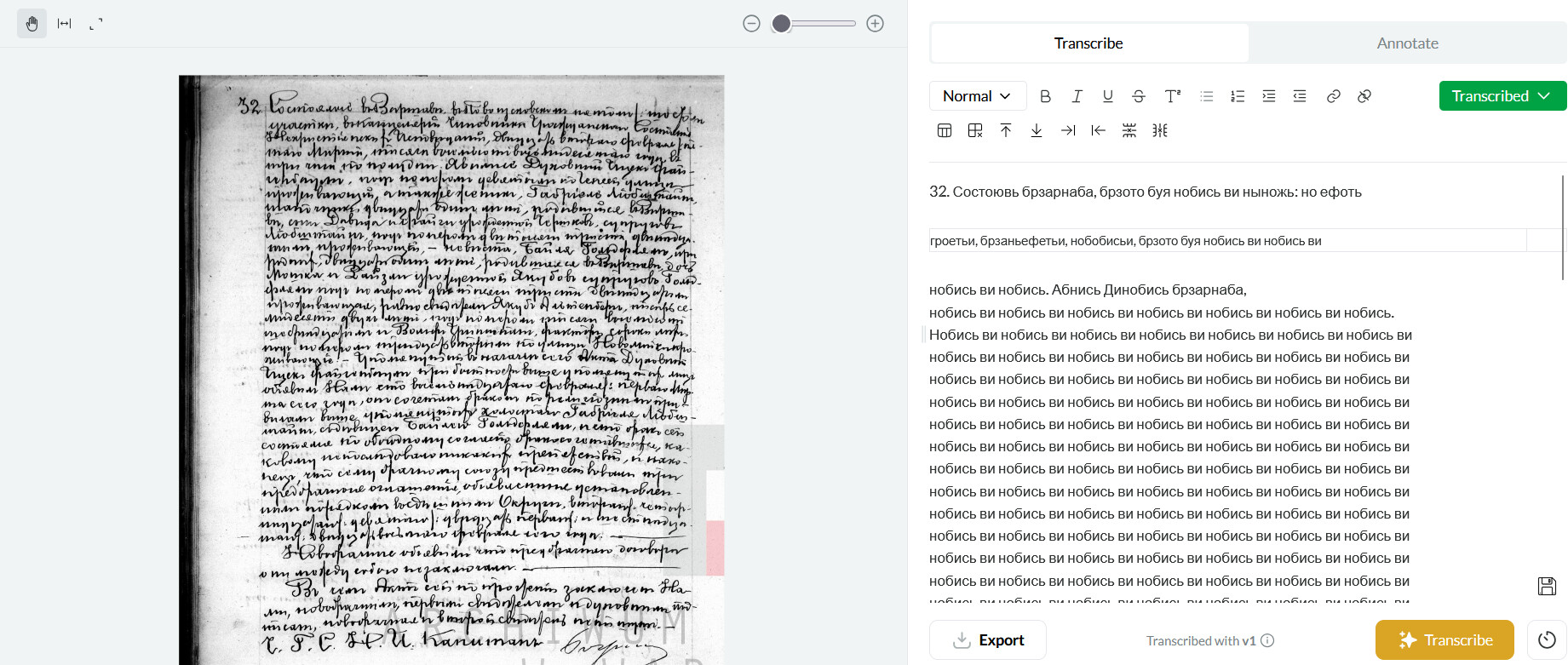
When I transcribe one document of several pages, Leo sometimes skips some pages and refuses to transcribe them even after I press “transcribe” manually. At the same time, it transcribes other pages of the same document quite well. Although all pages are of the same quality, it recognizes selectively and does not transcribe a single word from the pages it skips. In this case, I think it is not the quality of the images, but a system error. One example: here you can see a perfect transcription, but some pages of the same quality from the same document remained untranscribed. I saw that other participants also have had this problem.
-
My photos of the microfilms from the screen.
Leo transcribes a text from low quality images, but with a lot of typos. This nevertheless makes the work easier, because when editing the recognized text it is easier to correlate the transcription with the document, but in this case almost every word contains many typos.**


What Leo transcribed here: “Через неделю Н. Н. Аверисов читал дсклад “Театр для себя” В Нсйбре ссстасдись две лекции, пssвященные театру- А. Амитатрсва “Бедкие трагки” / Рссси и Саьвиии / и К. Микламовскисс "Кснкуренцки или синтез”.
What must be (misspelled words in bold): “Через неделю Н. Н. Евреинов читал доклад “Театр для себя”. В ноябре состоялись две лекции, посвященные театру - А. Амфитеатрова “Бедные трагики” / Росси и Сальвини / и К. Миклашевского "Конкуренция или синтез”.
-
Pre-revolutionary spelling.
Printed text in pre-revolutionary orthography is recognized very well, with only minor typos! -
Handwritten.
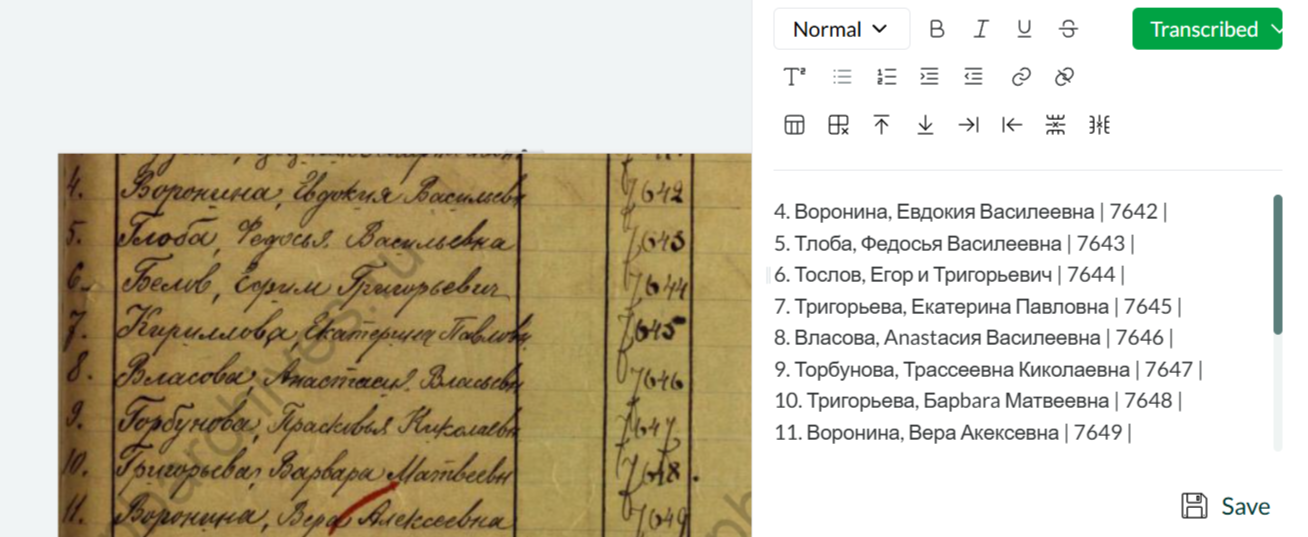
Leo is good at transcribing good quality images with handwritten text. In this example you can see the very legible handwriting of the scribe. Some mistakes here:
-
- must be Белов instead of Тослов, Григорьевич instead of Тригорьевич;
-
- must be Григорьева instead of Тригорьева;
-
- must be Горбунова, Прасковья Николаевна instead of Торбунова, Трассеевна Киколаевна;
-
and some other similar errors based on substitution Г by T.
-
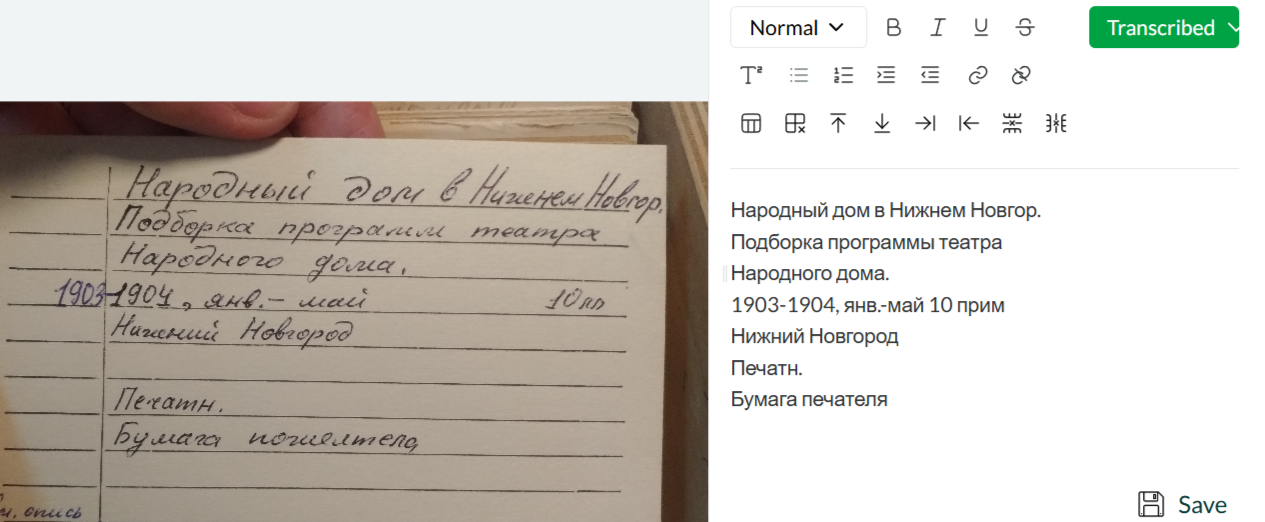
A good example - only 1 error (must be бумага пожелтела instead of бумага печателя):
- Handwritten bilingual
With handwritten texts I also have found that it is yet difficult for Leo to recognize two languages in one document: it usually transcribes the overall text in a language that comes first in a source. For example, at this postcard the address is in French and the main text in Russian but Leo tries to transcribe everything using Latin letters: