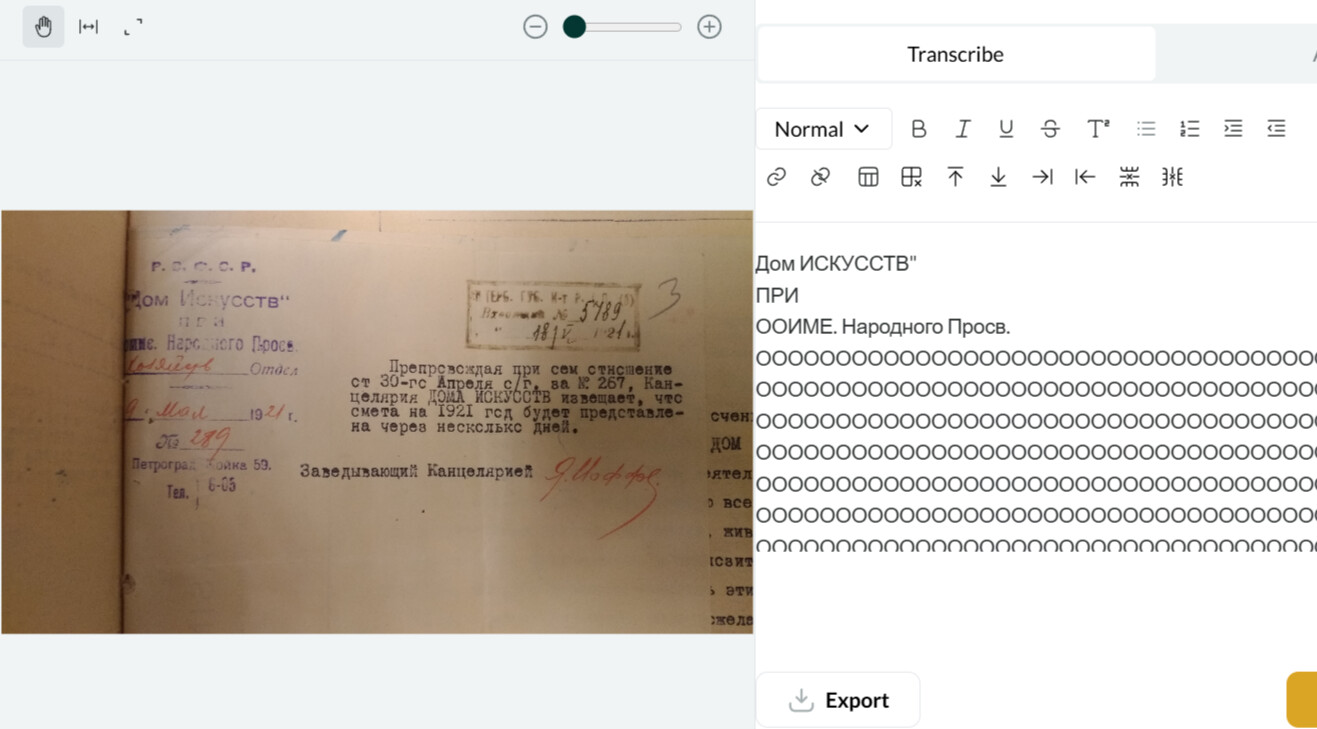
I’m having a new issue! My transcription started out alright if a little inaccurate, but soon just became a repeat of the same three or so lines, over and over again… I’m attaching a screenshot so you can see what I mean.
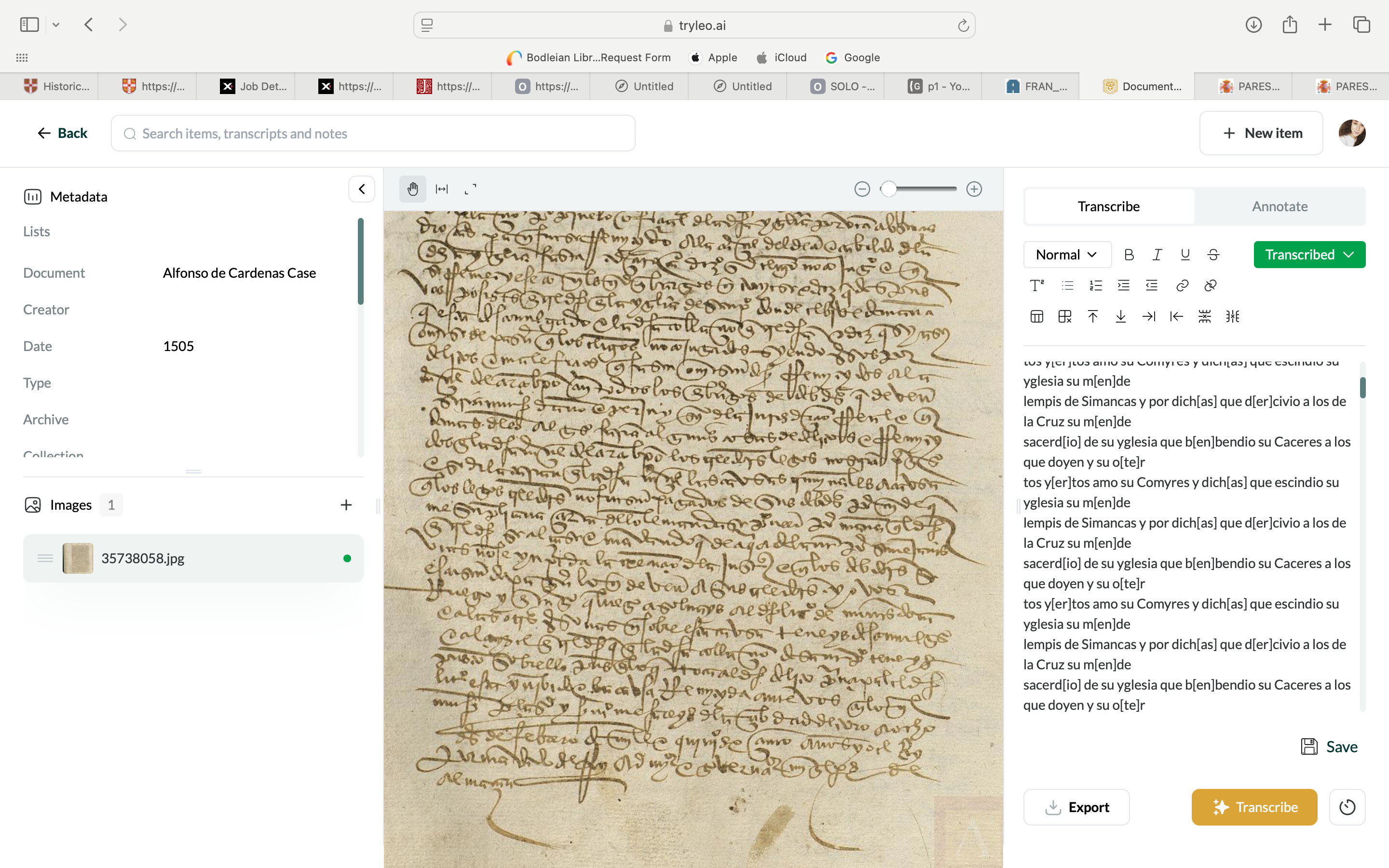
Thanks for this Clare. Please see here for some guidance on hallucinations. Hopefully these will be less common in the next iteration of our model. In the meantime, it’d be super helpful if you could tell us anything you notice about the kinds of images that Leo tends to struggle to transcribe accurately.
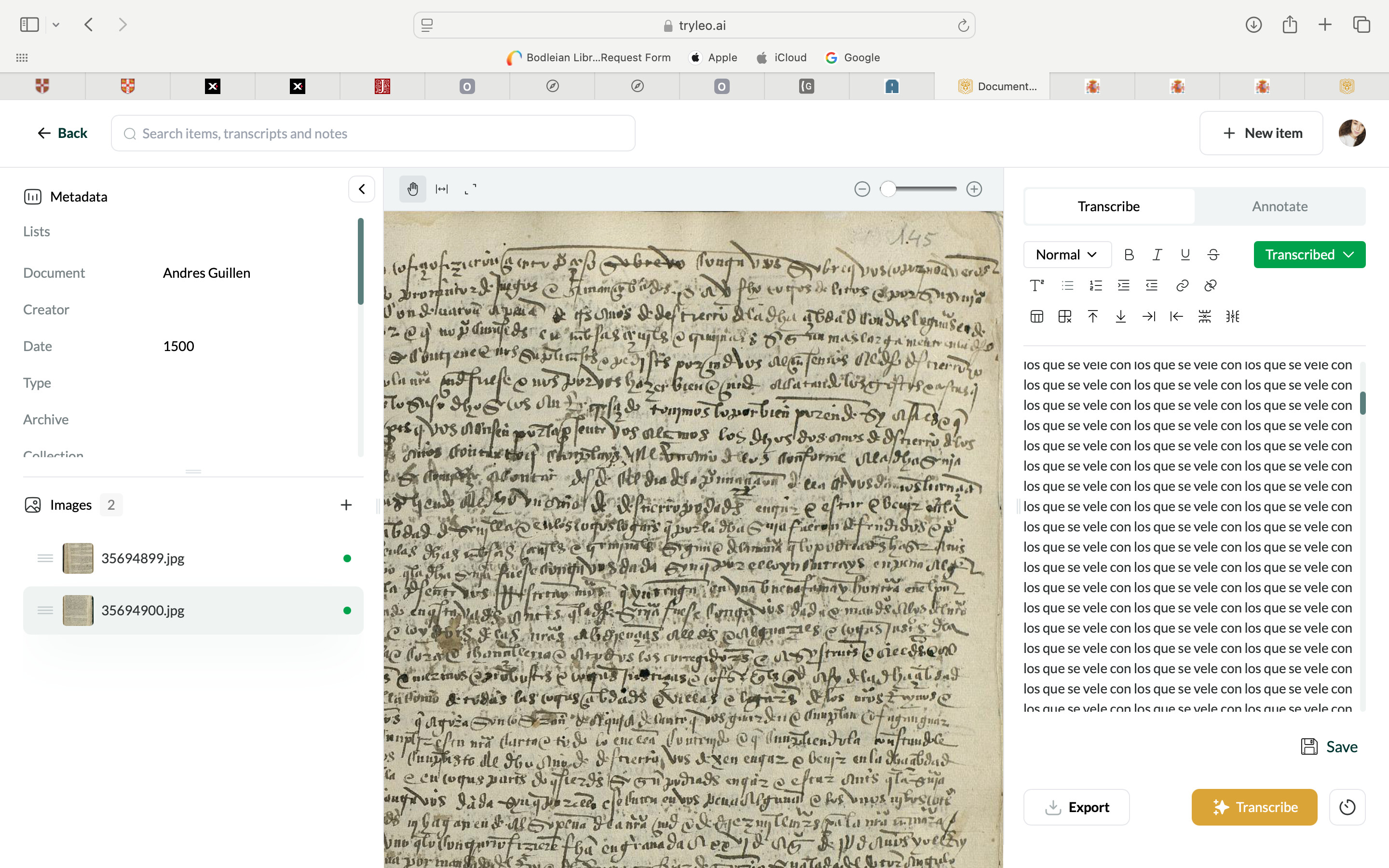
I have had the same problem w/ transcriptions from French. In some cases, the uploaded image included some text from the following page which I could crop to fix. The attached screenshot seems like it would be fine, but Leo still struggles with it.
Hi there! I had the same issue with a text in Russian which seems to be quite legible!
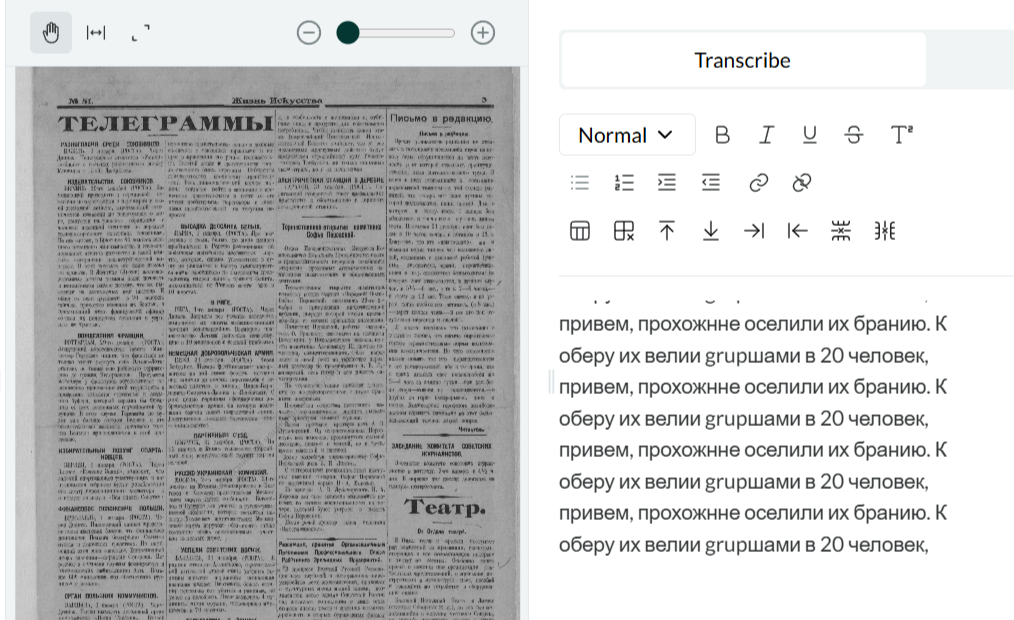
Another example:

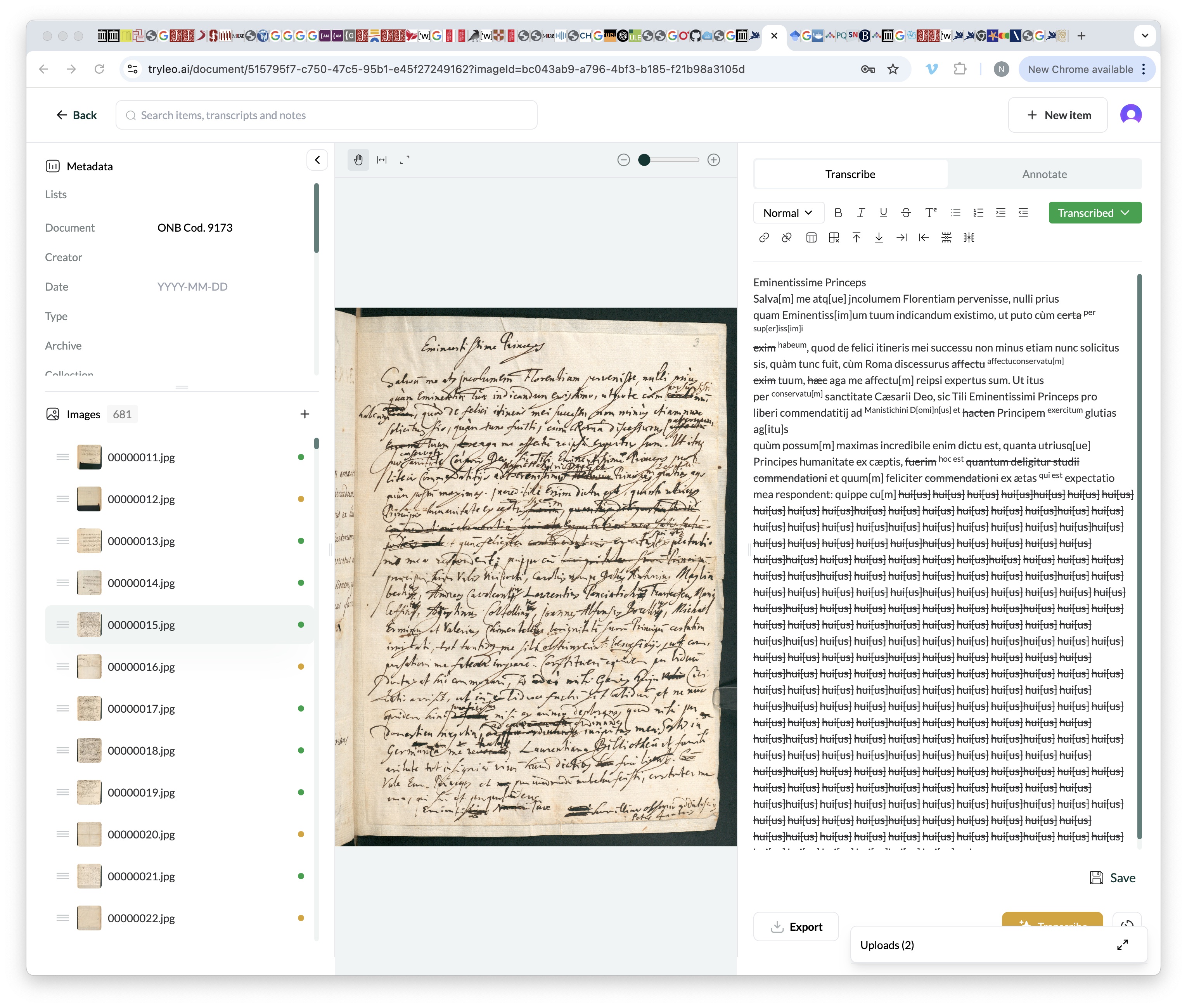
I noticed I got this problem a lot in ‘drafts’ - heavily marked up by the author, lots of cross outs:
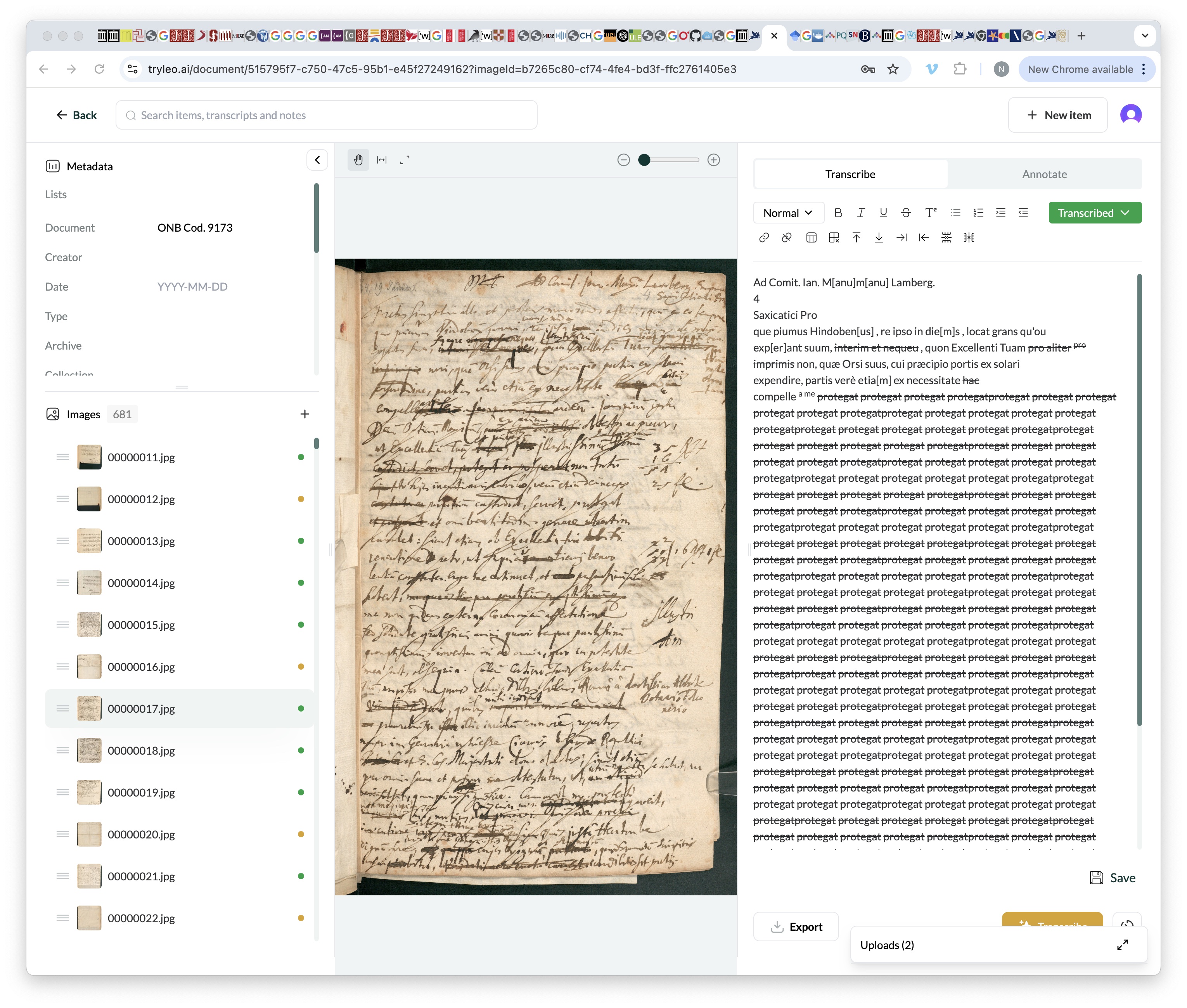
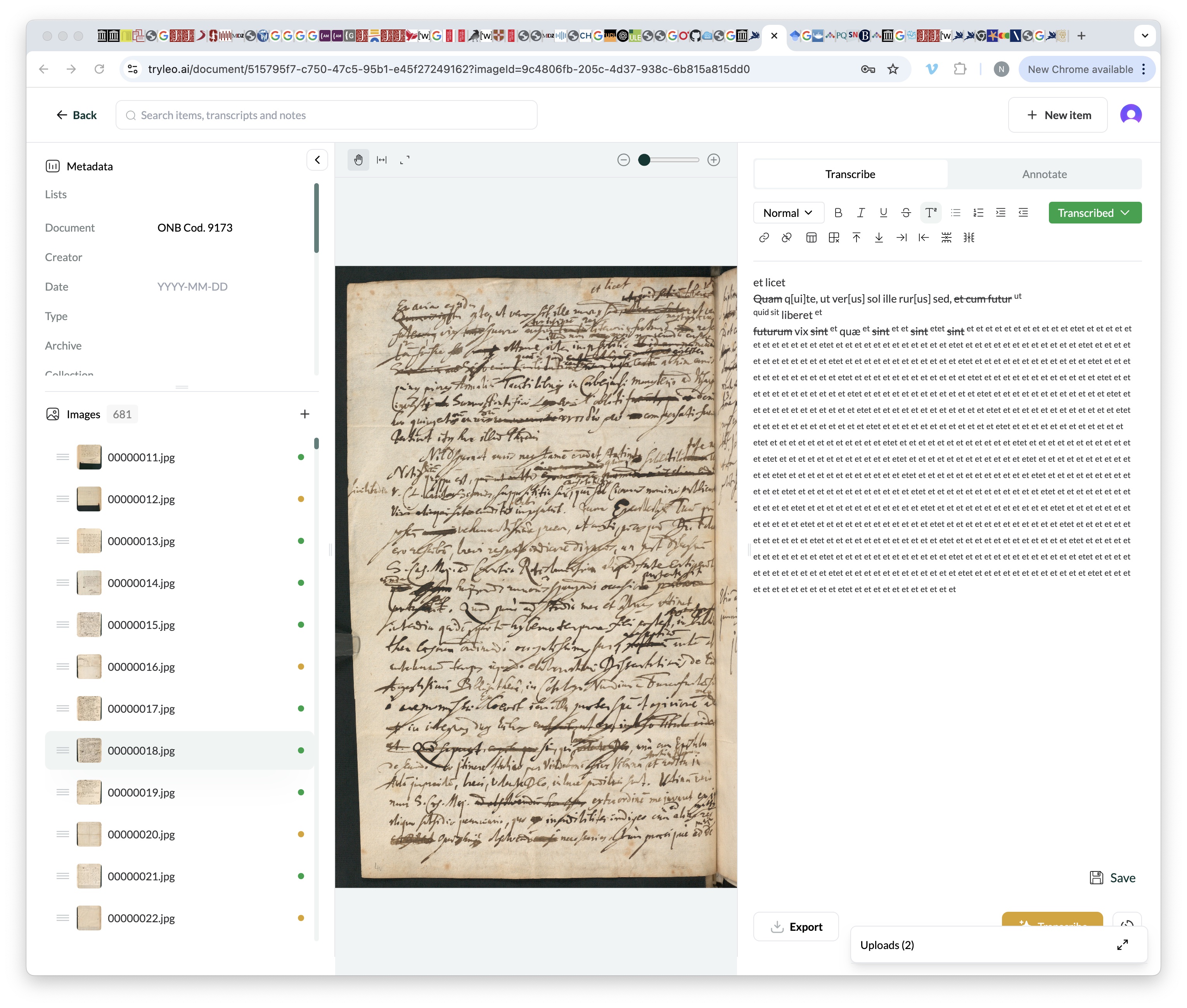
1 Like
Yes, this is a known issue with rotated images—we’ll be introducing image manipulation tools soon and the next model should be better at dealing with them.
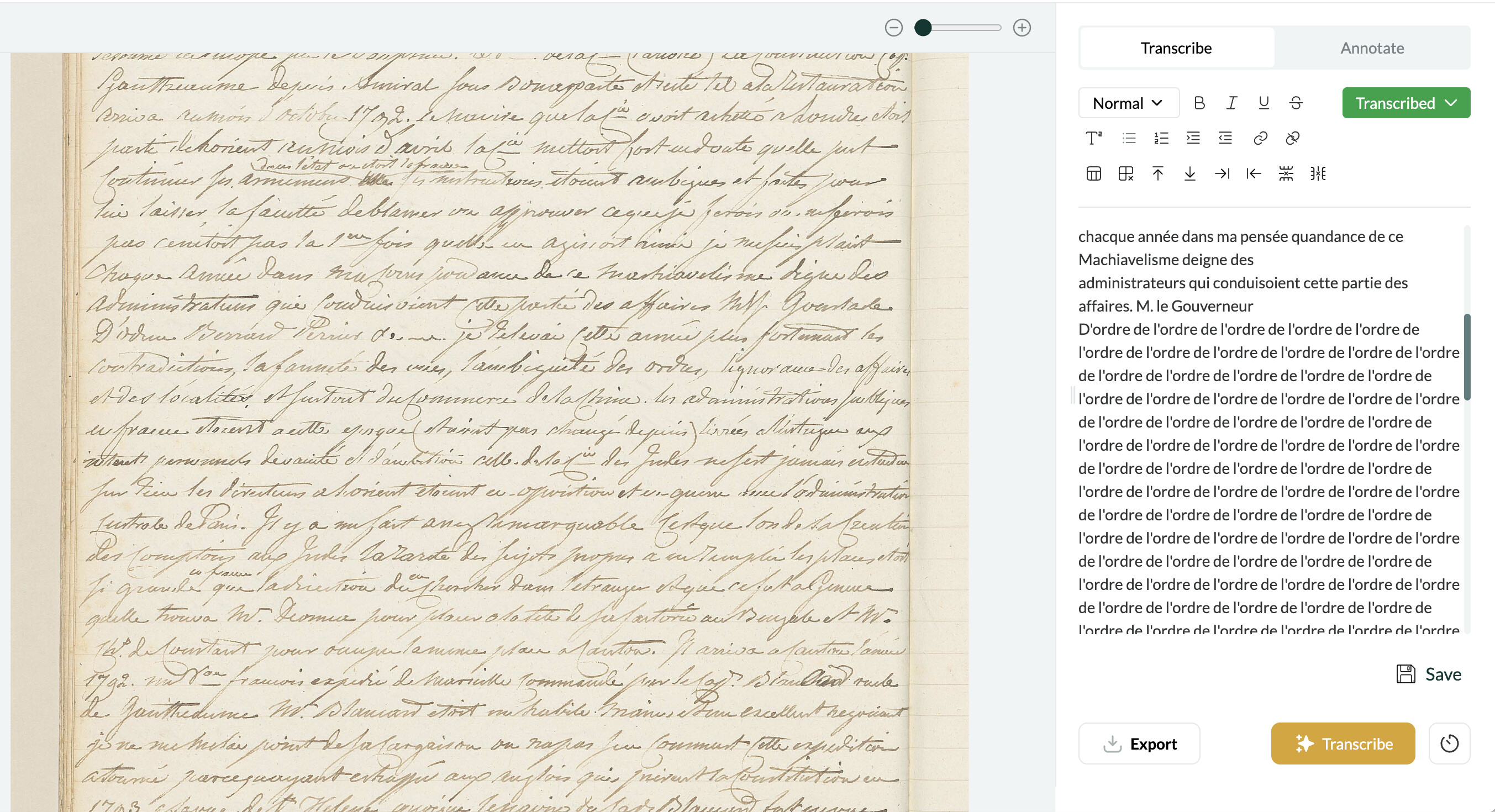
I’ve had the same issue with 20th century French. I noticed, however, that this error seems to occur when identical phrases are repeated in the same relative location on successive lines. E.g., on this page the text reads: “… c’est ainsi qu’il est retourné à la maison avec son enfant et un autre homme; c’est ainsi qu’après il a tué sa femme…” (sorry, it’s a murder trial). The issue seems to be that “c’est ainsi” appears twice, near the end of the line each time; Leo then gets stuck in a loop.

1 Like
I have had the same issue - unfortunately I’d already deleted the text and re-transcribed manually, but in my case it’s handwritten 19th century English, quite legible - the image is rotated sideways which I think is causing this problem
1 Like
Yes. It’s highly recommended to rotate your images the right way around before uploading! We’ll be introducing image manipulation features within the app to help with this soon and the next model should be much better at dealing with rotated images in the first place.

Had a repetition today in a transcript - seems to be because there is a darker patch on the page and once Leo hit that darker patch it just didn’t transcribe the rest of the document, despite the writing and photo being quite clear.
This is a legal bill from the court of Exchequer. These bills generally have stains, holes, and ink blots etc on them, and a few other transcripts with these same features have also thrown Leo in the same way. I don’t know if there is a way to train it to get round these kind of issues? Or for it to come up with a special character to insert in these cases that signifies a hole/discoloured section/?
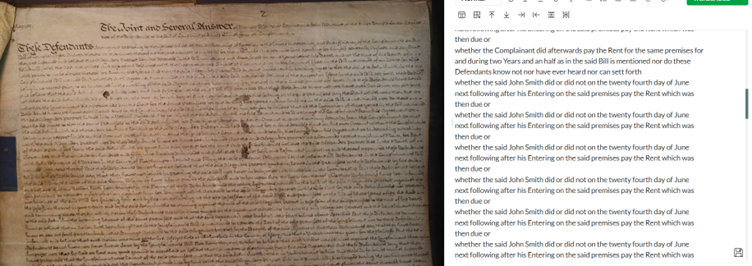
Thanks for this! See here for what I think is the main issue here: Problems with marginalia - #5 by Jon
That said, it’s likely that ink blots, stains, etc. are also contributing factors. We’re planning to train a future version of the model on distorted text like this so it gets used to them—it just costs a bit more to do!
1 Like
I am having similar problems. The first word is correct and then nothing else. Pure repetition.