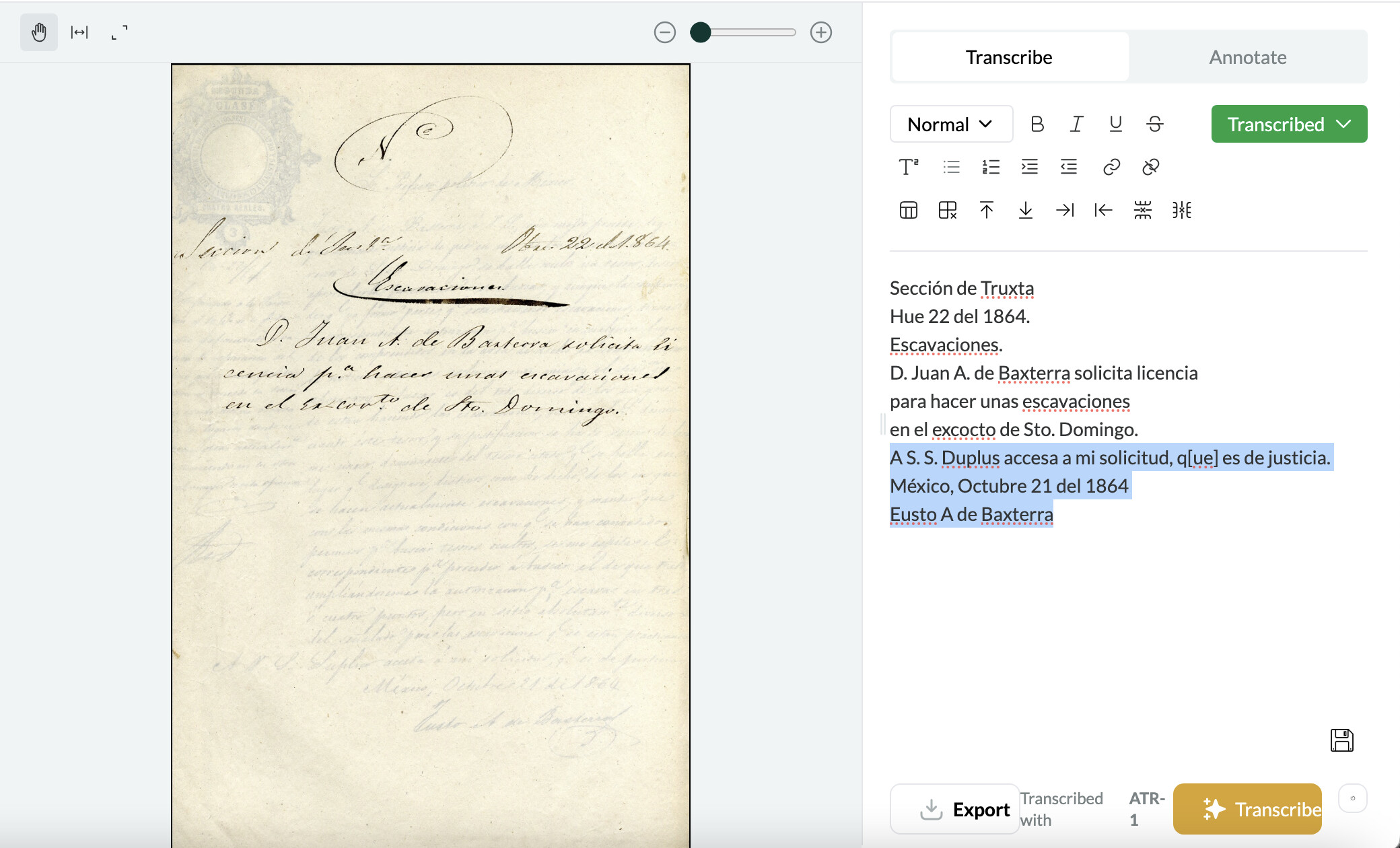
A recent transcription included three lines of text from the following page of a document (highlighted in the screenshot) that are visible through the thin paper. In some ways this may be a good sign that the model is able to read very faint text. I’m not sure how you would go about having it differentiate layers of text from different pages.
1 Like
Ah, interesting. Leo ideally wouldn’t read through the page, but only transcribe what was there. The plan for the next cycle of training is to introduce more distorted images (e.g., high and low contrast) into the dataset so it should get better at figuring out what’s on the page that’s actually been photographed.
1 Like
For my letters Leo did a good job of filtering out and not transcribing text that was on the backside of the paper that had bled through.
1 Like