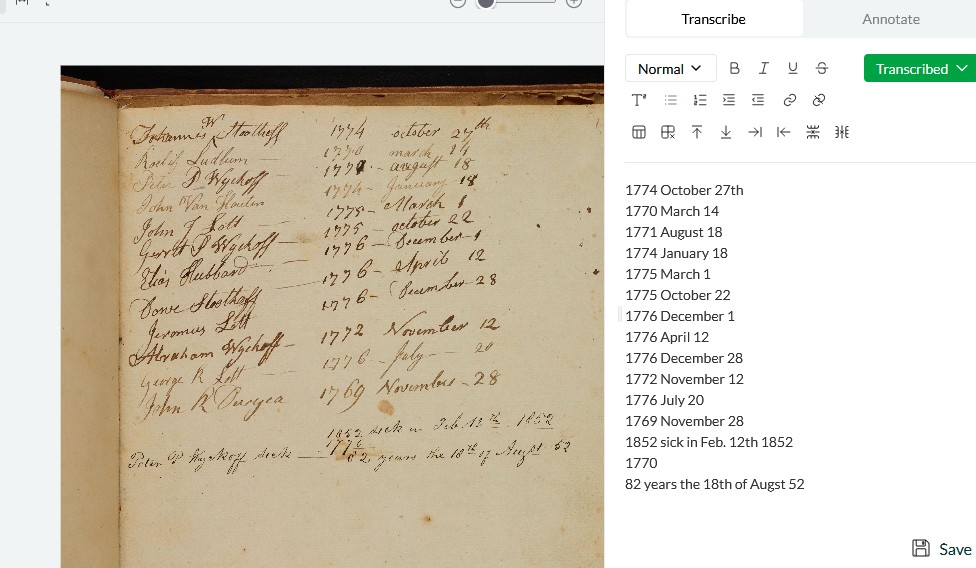
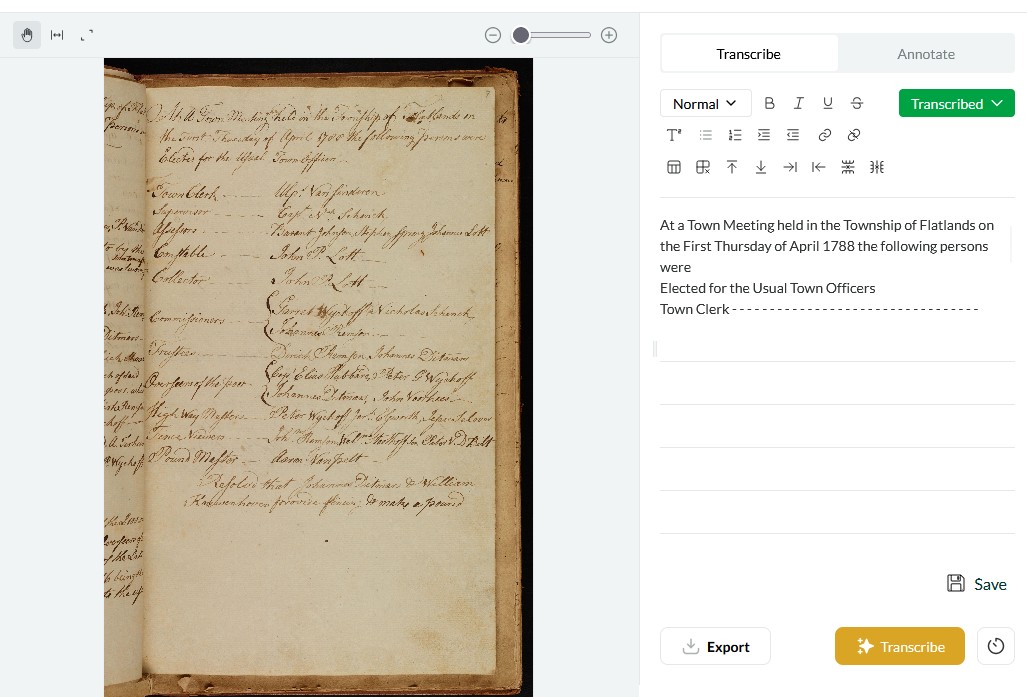
A consistent issue I’m having with transcriptions is Leo’s inability to recognize columns if there are no dividing lines. (This is similar to some of the marginalia issues it seems others have encountered, but distinct.)
In many of my documents, as is common in 19th/20th-century French state archives, there is a “heading” in the upper left-hand corner, which can sometimes extend quite a bit down the page. (See examples below.) Leo tends to jump between this “heading” and the main body of the page, rather nonsensically. It does not seem to record this left-side column as marginalia either, since there are no brackets.
Thanks Wallace. It’s super tricky to fix this but we’ve taken note and will think about how to incorporate fixing this kind of stuff into the data cleaning pipeline. But it’s probably a question of upgrading the base model on which we train Leo. We’re preparing for this now and within a couple of months we’re planning on a major model release where you should see significant improvement with issues like this!
I’m having a similar issue, sometimes leo recognizes without any difficulty that letters are written in two columns on the same sheet, sometimes not. I don’t have any good ideas about why it isn’t recognizing the columns written in the following hand/format with similar ink
I have actually had good experience with recognizing columns, probably because I used the iPhone Notes scan function to put the original into black-and-white, and not in photo format? In that way it might have been easier for the recognition, I guess?
I was looking for this topic exactly because I have had good experience with column recognition, so many thanks to the Leo team. Maybe it’s also some recent improvements since April?
Oh I need to add: It worked for me best when the PDF I uploaded was in the right direction. When I have a two-column text but 90 degrees tilted, the recognition fails to capture which column goes first–it transcribed the right column first and then the left column. But that’s an easy fix in the eyes of the researcher, and I just want to bring this up as this modifies my earlier comment.
I’ve had some challenges with columns (it sometimes does not recognize the first column in US county court records, where shorthand detals about what follows are logged. For example, that first column might read: Jones to Sanders Deed T, indicating that the main body of the page would be the actual deed of trust between “Jones” and “Sanders”). It sometimes simply ignores that column. Similarly, in these same court records, there are sometimes accounts that have columns for purchaser, item, #, $, cents. It does not always recognize the far left columns (where the purchase amounts are located). Does it matter if we are uploading images that in color? Does converting images to B & W help? And, if we are working from a large bound book, sometimes the pages curve toward the binding–wondering if that curve can create issues with recognition and transcription?
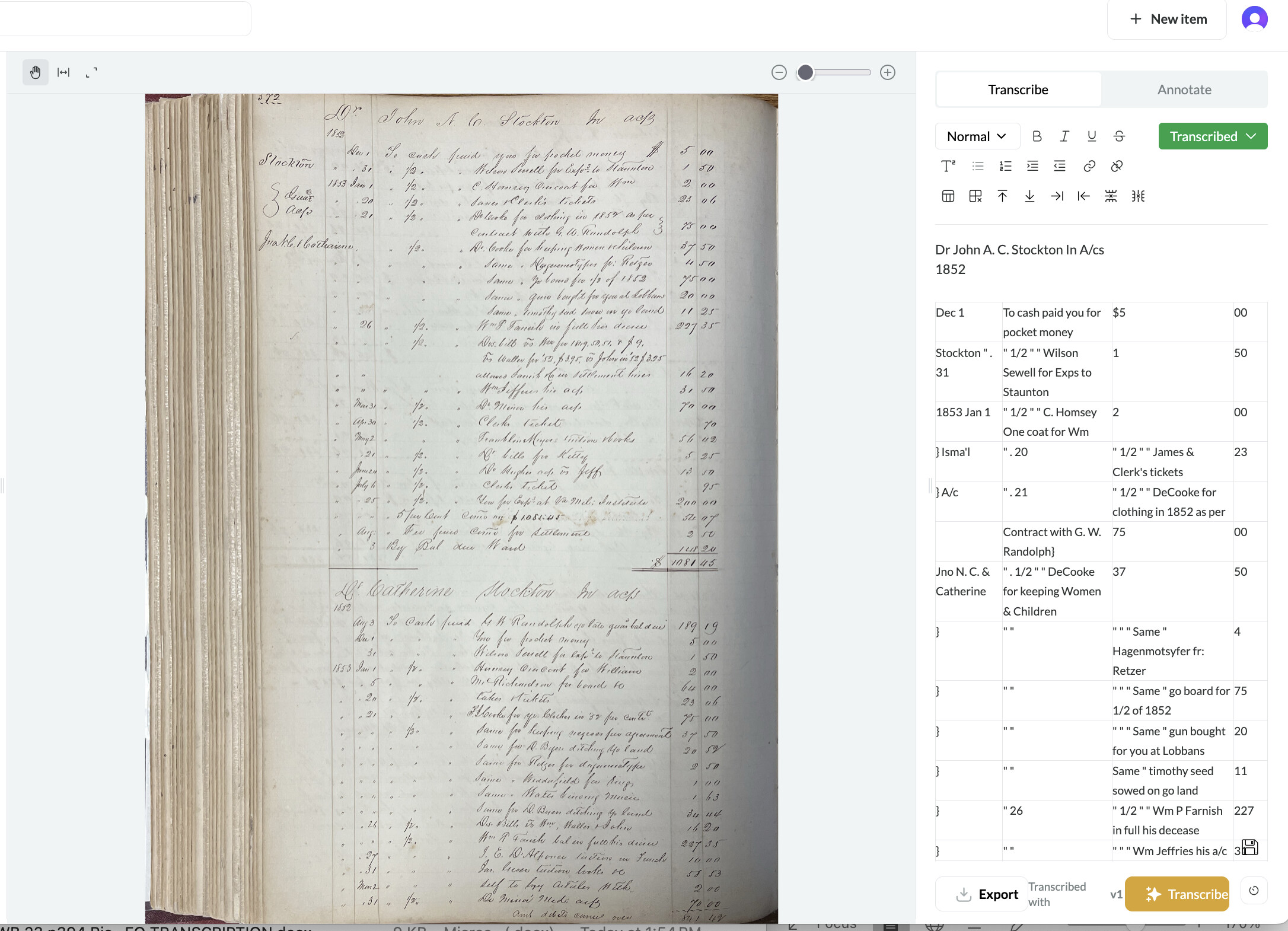
Second question here related to transcription of accounts with columnar organization. I’ve attached a screenshot of a 19th century US county court estate account that I uploaded to LEO. You can see here that the transcription viewer to right puts it into a chart with columnar form, but the transcription, when downloaded as Word file, looks very different (text is correct, but formatting does not adhere to original). Is there a way to ensure that the transcription is faithful to the framework or structure of the original (as well as accurately transcribing text)?
Word transcription looks like this: 1853 ACWB 22 p372 John NC Stockton estate accts (JBMinor)-image-1.png
Transcript:
Dr John A. C. Stockton In A/cs
1852 Dec 1 To cash paid you for pocket money $5 00 Stockton " . 31 " 1/2 " " Wilson Sewell for Exps to Staunton 1 50 1853 Jan 1 " 1/2 " " C. Homsey One coat for Wm 2 00 } Isma’l " . 20 " 1/2 " " James & Clerk’s tickets 23 } A/c " . 21 " 1/2 " " DeCooke for clothing in 1852 as per Contract with G. W. Randolph} 75 00 Jno N. C. & Catherine " . 1/2 " " DeCooke for keeping Women & Children 37 50 } " " " " " Same " Hagenmotsyfer fr: Retzer 4 } " " " " " Same " go board for 1/2 of 1852 75 } " " " " " Same " gun bought for you at Lobbans 20 } " " Same " timothy seed sowed on go land 11 } " 26 " 1/2 " " Wm P Farnish in full his decease 227 } " " " " " Wm Jeffries his a/c 31 } " Mar 31 " 1/2 " " Do Minor his a/c 70 } " Apr 30 " 1/2 " " Clerks ticket } " May 2 " " " Franklin Moyer tuition books 56 } " . 21 " 1/2 " " Dr bills for Kitty 5 } " June 24 " 1/2 " " Do Hughes a/c vs Jeff 13 } " July 6 " 1/2 " " Clerks ticket } " " 25 " 1/2 " " You for Exps at Va Mil: Institute 200 } " " " " 5 per Cent Com[m]o on: $1081.45 } " Aug: " Fee paid Com[m]o for settlement 2 } " 3 By Bal due Ward 148 $1081 Dr Catherine Stockton In A/c’s
1852 Aug 3 To Cash paid G W Randolph go late quar[an] bal due 189 19 Dec 1 " " " You for pocket money 5 00 31 " " " Wilson Sewell for exp[er]ts to Staunton 1 50 1853 Jan 1 " 1/2 " " Hunsey One coat for William 2 00 } " " 5 " " " Mr Richardson for board &c 64 } " " 20 " 1/2 " " taken tickets 23 } " " 21 " " " F. A. Cooke for yr. Clothes in '52 per cont[en]t 75 } " " " " 1/2 " " Same for keeping negroes per agreement 37 } " " " " " " Same for D. Byers ditching go land 20 } " " " " " " Same for Retzer for daguerreotype 2 } " " " " " " Same " Waddafield for rings 1 } " " " " " " Same " Water binding music 1 } " " " " " " Same for D. Byers ditching go land 34 } " " 26 " 1/2 " " Drs Bills to Wm, Waller & John 16 } " " " " 1/2 " " Wm P Farnish bal in full his decease 227 } " " 27 " " " J. E. D’Alpence tuition in French 10 } " " 31 " " " Jas. Green tuition books &c 58 } Mar 2 " " " Self to buy Articles with 2 } " " 31 " 1/2 " " Do Minor Med: a/c 70 Amt debits carried over 841 42
──────────────────────────────────────────────────────────────────────
Thanks for this Kirt! I’m not sure whether uploading the images in black and white would help. Probably not, but you could try it. It just depends what the model is seen and what statistical patterns it has “learned” from that data. If tables happen to be transcribed more reliably on images of curved pages in the training data, for instance, then Leo will prefer these. It has… distinctly non-human sensibilities! In any case it’s good to know what’s not working well so I’ll pass this feedback onto Jack and hopefully it will help his work on the next model, as we continue trying to get structured layouts like this transcribed reliably. Thank you!
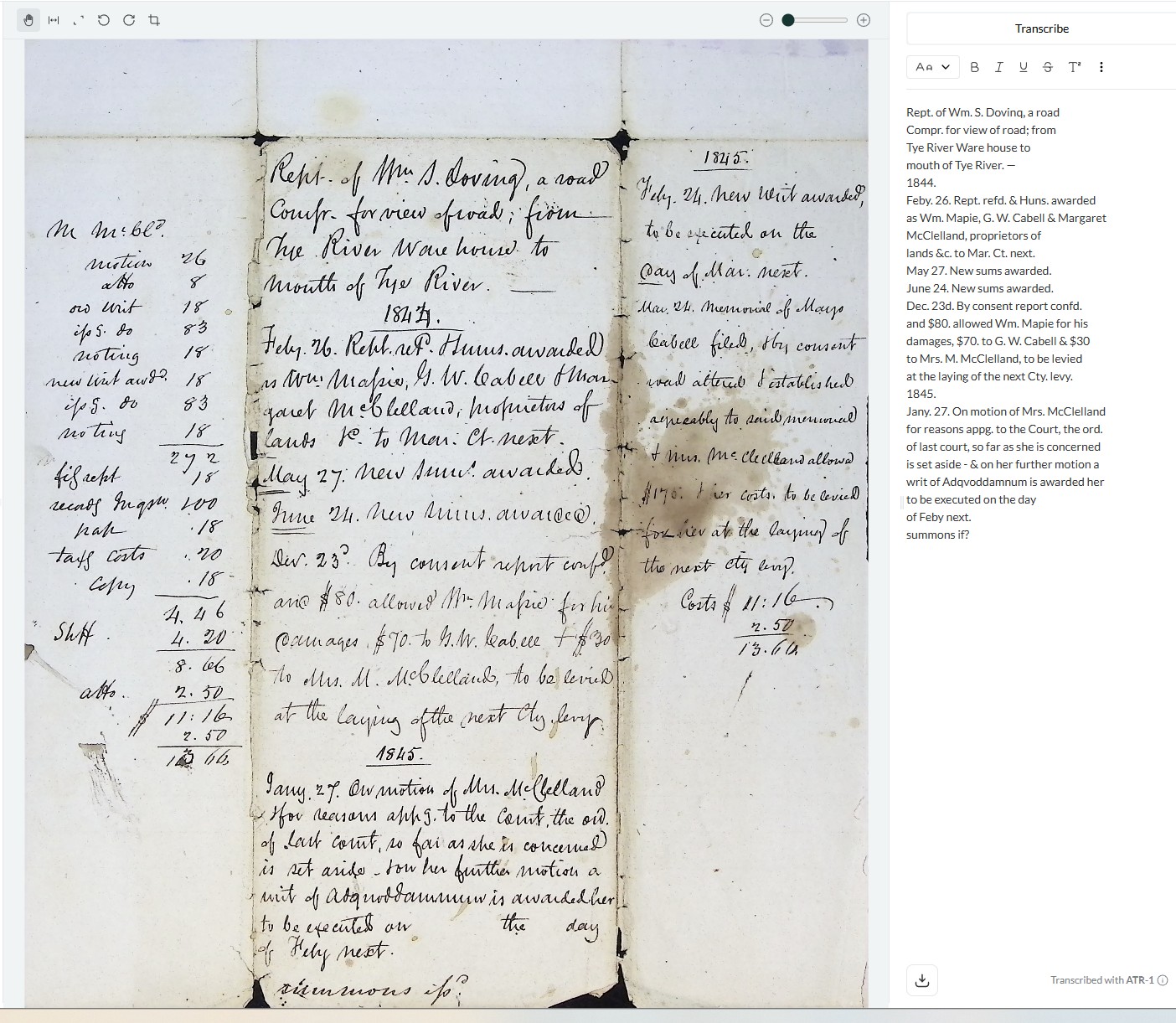
The biggest error in the accuracy of transcriptions was Leo’s ability to recognize and transcribe different sections of text on a page. When text was divided into more than two columns on the paper, Leo only transcribed one of the columns, usually the center column. It completely ignored the other columns of text. Leo does not always transcribe the (columns of) text in the order in which it was written. It would be very helpful if Leo identified section/column/page breaks in the transcriptions. When text is written vertically in the margins Leo sometimes uses ‘< >’ marks to identify this text, but not consistently enough and it never appears in the same place in the transcription.
Letters were written on paper that was folded multiple times, thus creating numerous sections to the letter. Letters were flattened and the entire piece of paper was scanned as a single image, thus creating multiple sections of text within each image. Leo did a fairly good job of identifying the beginning of the letter but did not always transcribe the other sections in the correct order, if Leo transcribed them at all.