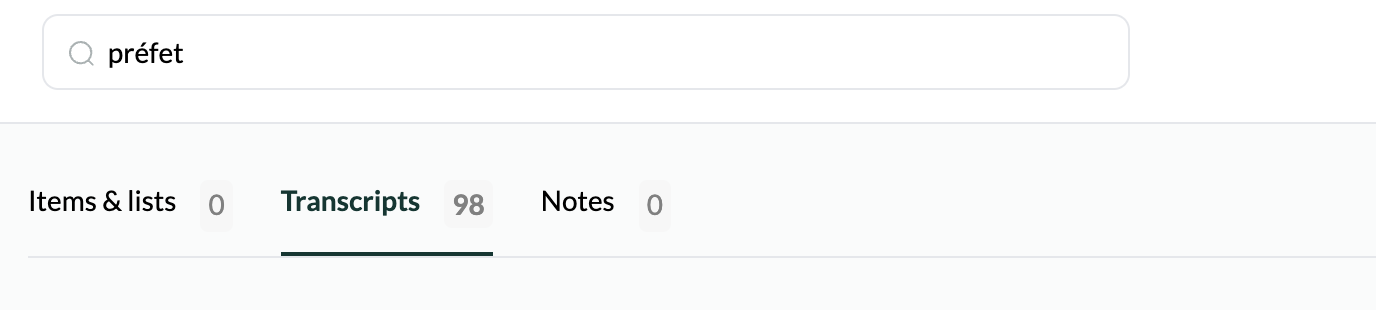
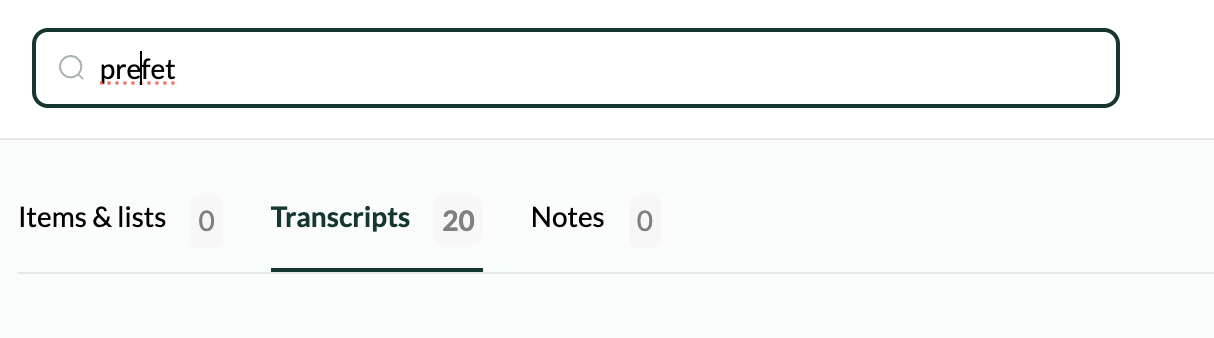
This is particularly relevant to languages other than English which make far greater use of diacritics/accents on letters, e.g. é, à, etc. The ‘search within transcriptions’ functions seems to distinguish between, e.g., é and e. This makes searching difficult when the transcription has failed to identify (or incorrectly added) an accent.
For example, the correct spelling is ‘préfet’, not ‘prefet’, but you would need to search for both terms to get an accurate list of results, as seen by the differing number of results for each search query below:
I suppose the trouble is that there would be instances where this distinction would be useful, but you could add an ‘ignore diacritics’ option.
Edit: this would presumably also be true of ambiguous punctuation, e.g. commas and full stops, colons and semicolons, em dashes, en dashes, and hyphens etc
Thanks for this Conor. I definitely see the issue here. The search function is currently just a simple, case-insensitive string search, like Ctrl+F. We had to make a decision in the winter about whether to begin with this or to develop a slightly more elaborate search function (PostgreSQL’s full-text search), which would handle word variations, partial matches, and would rank results by relevance. The problem with the latter option was that it would take a while to build yet would quickly become redundant.
Our goal for Leo is to have true semantic searching, which means to search for a meaningful concept rather than exact token overlap, so that any given query would also find results for roughly the same idea expressed in other lexical forms like synonyms or paraphrases. So if you searched for, say, the “glorious revolution” in eighteenth-century British pamphlets, you would also get hits for “the bloodless revolution”, “the happy revolution”, “the restoration of our liberties”, or “the great deliverance” when these referred to the same event. To do this will take time and investment. We’ll need to create quality embeddings and a vector-search layer, make it work with other metadata filters, build evaluation tooling, and integrate this system into Leo’s user interface. Of course, once it’s done, the problem with diacritics would disappear altogether.
It’ll be a little while until this is fully put together but I’ll talk with Jack and see if there are any small things that we can do to improve the search feature to tackle this and similar issues with near results in the meantime.