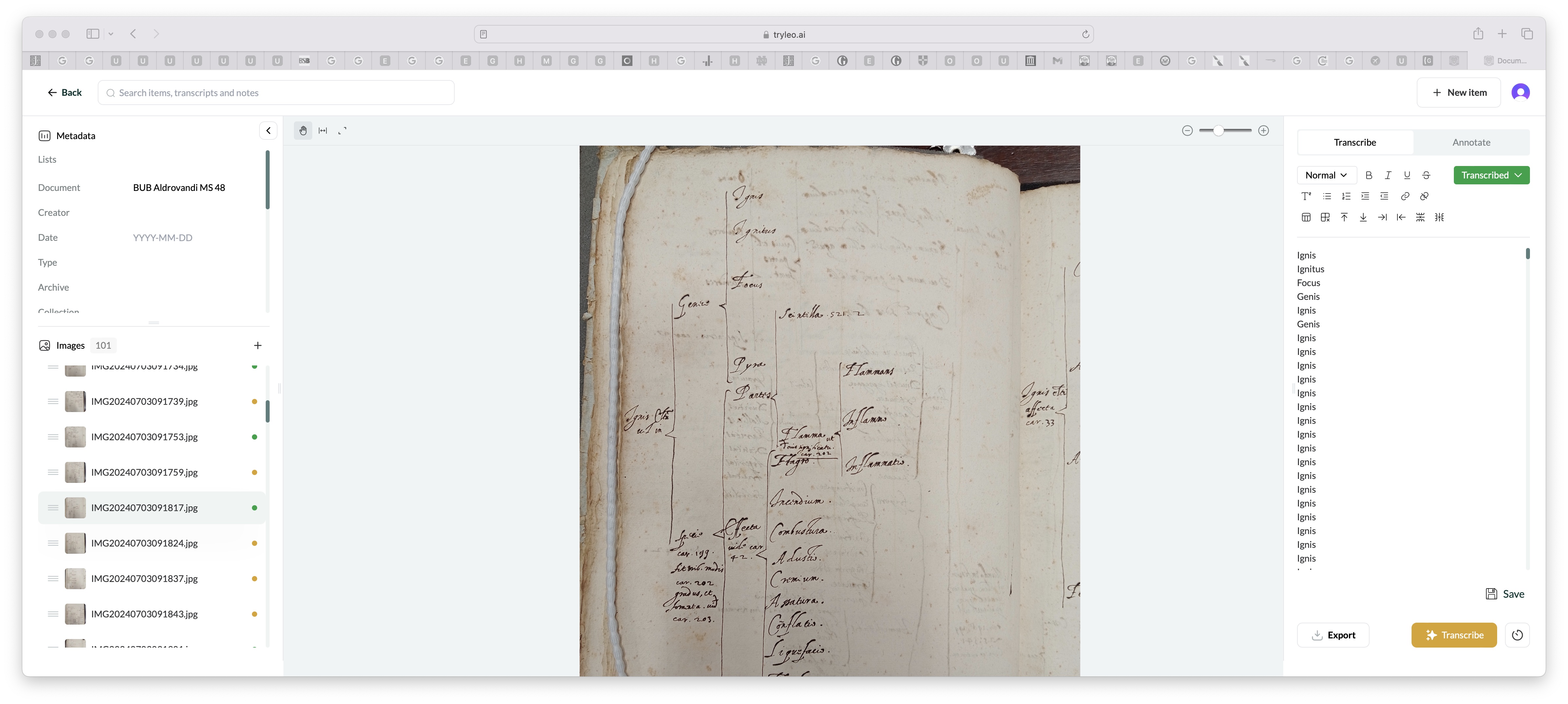
The model struggled to represent the text in a branching diagram. Just flagging it as something it struggled with.
1 Like
Thanks for flagging this Noah—it’s definitely something we can work on. I think I’ve seen Leo work by representing up to two levels of brace notation with curly left brace symbols. If we could get more levels to work consistently, what do you think would be the best way of representing a branching diagram like this? We’ve currently been working with HTML tables for complex segmentation. But maybe there’s a better way in this case?
In print I’ve sometimes represented branching diagrams using you know outlines, like
- Genere
a. Ignis
b. Ignitus
c. Focus
etc. I don’t think that’s a great solution, I don’t think there is a good solution in a text box. But for my use the main thing is not getting the spatial elements right but making sure the thing can transcribe words properly when confronted with unusual spatial arrangements. Because there are loads and loads of different kinds of unusual spatial arrangements. This is not even an unusual one!
1 Like
That’s good to know. I think we do want to include the spatial elements for users who would find it useful. The reason why the model often struggles to parse segmentation isn’t so much because it doesn’t know how to do it. In some cases it can. The problem is just that it gets confused because tables / branching diagrams like this are represented in so many different ways in the training data. So for the next major release of the model we’re thinking about ways to clean the data so that it always follows a consistent pattern.
For non-enumerated, hierarchical lists we could try something like this (the model would then add any numbers/ letters as they appear in the original manuscript)
Root
├── Branch
│ ├── Sub-branch
│ ├── Sub-branch
│ │ ├── Leaf
│ │ ├── Leaf
│ └── Sub-branch
├── Branch
│ ├── Sub-branch
│ ├── Sub-branch
└── Branch